
How much capacity will you need for your app?
Or asked another way if wearing the vendor hat, how much money ya got?
We’re generally lousy at estimating infrastructure capacity requirements and even when a more scientific approach is taken (and it’s frequently not), we’re still lousy at estimating user behaviour in real world circumstances and the impact it will have on system performance.
Now, put that situation in a cloud environment and it has the potential to go a couple of ways. One is that you have underestimated and by courtesy of the glorious ability to increase resource very quickly, your bill goes nuts. Another is that you’ve overestimated and you end up paying for resources you really don’t need. I’ve recently gone through scaling challenges with both the website and the Azure SQL database on Have I been pwned? (HIBP). For me, it’s never about having access to enough scale (that’s pretty much limited by your wallet), rather it’s about trying to both keep the cost down and the perf up and frankly, I don’t really want to compromise on either! Here’s what I’ve done with the website and I’ll write more about the database another time.
The website
I’ve been running on a single small instance of an Azure website since day one. 95% of the time, that’s fine and the other 5% of the time it either scales out automatically or… breaks. Let me explain:
Recently I wrote about Understanding Azure website auto-scale magic and I showed how I was supporting about 4k requests per minute whilst someone was hammering the API:
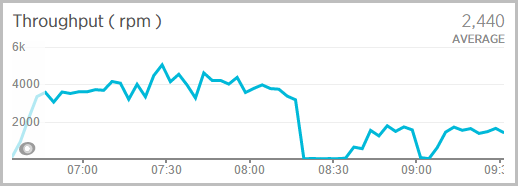
This was with two small web server instances:
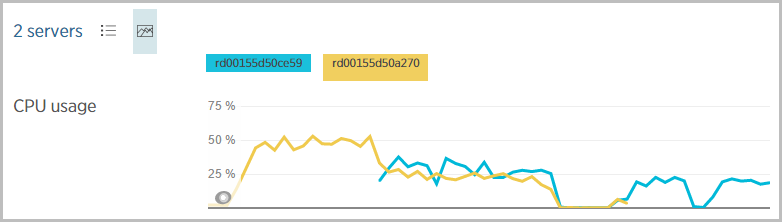
I tried scaling it out to three small instances and… the throughput stuck at 4k per min. Ok, so the consumer of the service is maxing out their ability to send and process requests, right? I mean adding more capacity on my end won’t improve things so it must be their fault. Sound thinking, or so I thought…
On a whim, I scaled up to a medium server size and then in so that there was only one of them and not two. This is exactly the same cost – two smalls equals one medium – and in prior load testing (you know, the kind where all the conditions are just perfect…) this resulted in exactly the same throughput. But this time, it doubled – I went to 8k requests per minute. The processing time for each transaction also went way down from about 60ms to around 30ms. Clearly, this was a significant improvement. Also clear was that getting scale right was hard:
3 small Azure website VMs serving 4k RPM at 60ms each. 1 medium and it's 8k and only 30ms at 2/3 the cost. Getting scale right is hard.
— Troy Hunt (@troyhunt) February 1, 2015 So why is this? Rob Moore made a good point that the small instance is only 1 core and that .NET garbage collection likes having a second one (or more) but on that basis, if your bottleneck is a single machine then two machines should double the throughput (although it could explain the 60ms to 30ms drop). Someone else suggested that it was related to the performance targets of the small machine instance but again, there’s nothing to suggest that two small instances can’t double the throughput of one, that’s the whole point of scaling out! But regardless of total throughput, the premise that a medium sized machine can process each request significantly faster than a small machine remains and that 60ms down to 30ms is certainly a very positive gain.
But here’s what really got me in terms of perf: my solution presently has these in it:
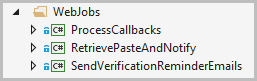
That’s three separate WebJobs that run as background processes. On every release, they need to be compiled and deployed as well as the website deployed – then they all need to be fired up too. I deploy from GitHub on checkin so Kudu comes into play which also runs on the same machine. The bottom line is that when I want to deploy while I’m using a small instance, this happens:
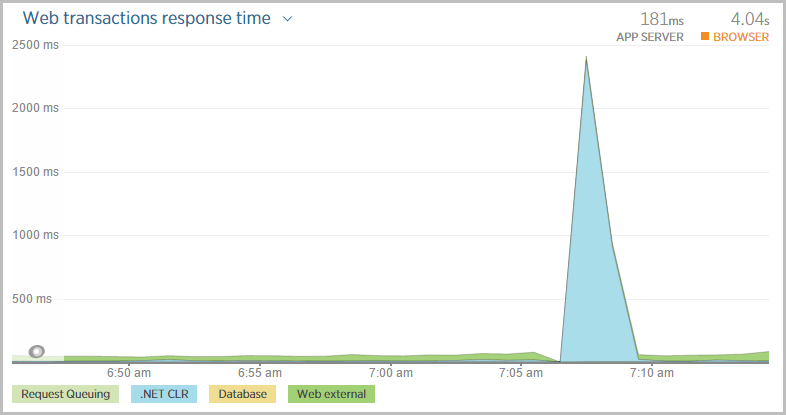
Whoa! That means my Apdex suffers and remember, this is what’s being observed in the browser:
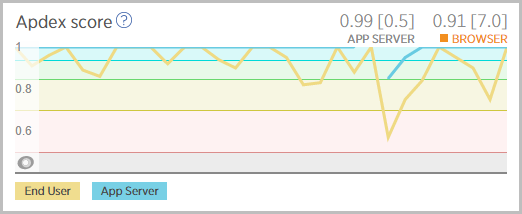
The throughput also goes to zip for a while:
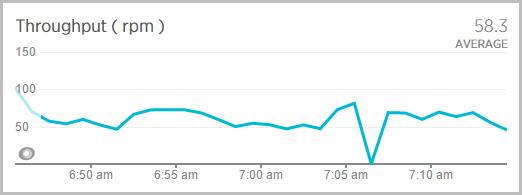
And the CPU, well, some data was lost altogether but clearly it’s approaching 40% utilisation:

This is during a period of light load too (only about a request for second), so imagine what it does once the load piles on. I lose traffic. I could change my workflow to deploy only to the staging environment and then use staged deployment slots to switch the traffic (and I do that at times), but I like to keep the app in a perpetual state of ready deployment and push lots of changes frequently. Using Kudu in this way and with the number of projects increasing and the codebase getting larger, I was causing outage.
Now let’s try that again with a medium instance of a website:
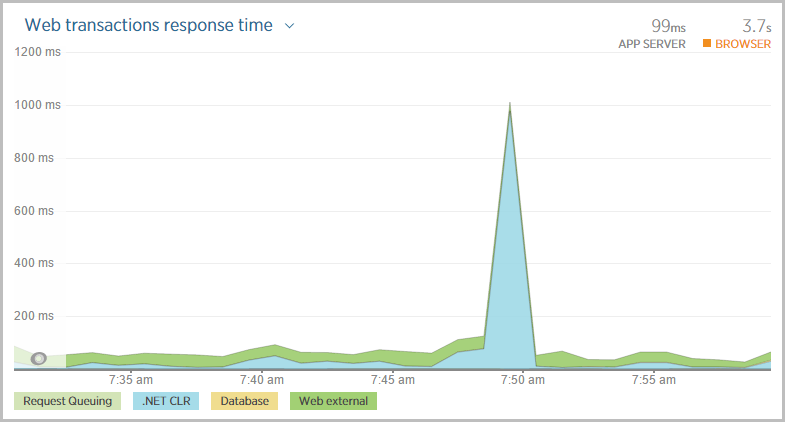
That 2.5 second spike is now 1 second. You’re still going to get a spike on deployment, but clearly it’s nowhere near as significant.
The Apdex stays much happier too – I’ve briefly dipped into “tolerating” (yellow) and not “frustrating” (red):
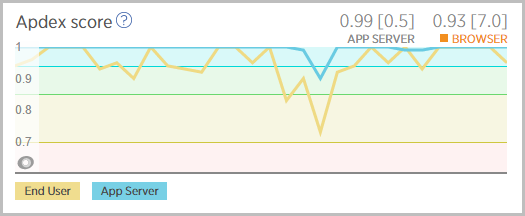
And the throughput never zeros out, in fact it doesn’t miss a beat:
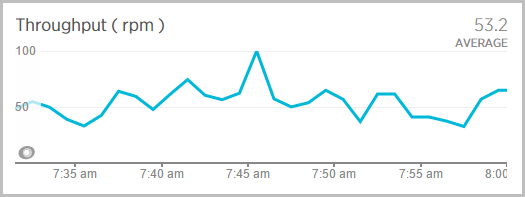
And the CPU utilisation stays way lower:

These results are all clearly just from one sample test, but what I can emphatically say is that time and again, I’d see high latency on response times, connections dropped and even total outage – sometimes for more than a minute – when deploying on a small instance. I’ve never seen loss of service or anything more than a slight and momentary service degradation on a medium instance. Not once.
Let me add something insightful for others interested in refining their scale:
Don’t treat your servers like pets, treat them like cattle
This is courtesy of Richard Campbell on RunAs Radio and what he’s saying is that sometimes you may need to just knock one off for the betterment of the heard. You can do that with Azure – flick a server out with another one and see how it goes. Don’t get an attachment to it like you would a dog, it’s a disposable service there to serve you and when you start viewing it as a highly transient resource, you can do a lot of awesome stuff such as figuring out what’s the best scale for you based on trial and error.
For me, it was chalk and cheese and the path forward was clear – I had to go from small to medium:
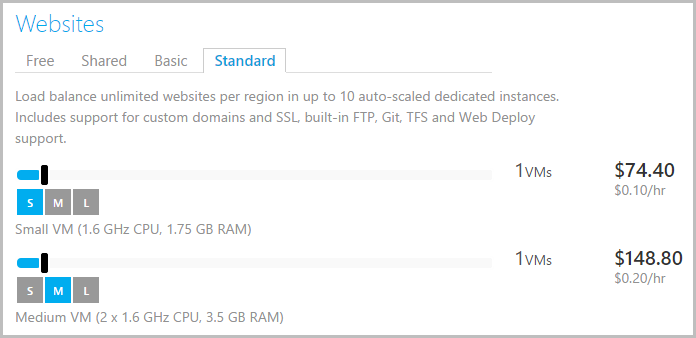
Yes, it’s an extra $74.40 per month – literally double – but it’s kinda not and there are other financial upsides too. Firstly, processing those requests at twice the speed (that’s never going to be a constant, but it’s a fair assumption to work with based on experience) has enormous upsides for volume consumers of the service. In this particular case, the consumer was checking about 10 million identities (something I’ll write about another time) and the medium instance reduces the duration of that by many, many hours.
The medium instance also means less notifications going to me when CPU load ramps up as it does so at half the speed for the same traffic volumes. Frankly, the peace and quiet is pretty valuable! But it also means that it scales later – I may be permanently running a medium instance, but there are heaps of times where I was running two smalls and paying the same amount so those periods cancel each other out.
But by far the biggest gain is that it means I can work in a more frictionless way. I don’t have to hack around the ways I release the software and I don’t have to spend time trying to keep things stable during the process. I push to GitHub, magic happens, then the production site is running the new version and everyone is happy. That’s worth a couple of bucks a day!