In the beginning, there was password hashing and all was good. The one-directional nature of the hash meant that once passed through a hashing algorithm the stored password could only be validated by hashing another password (usually provided at logon) and comparing them. Everyone was happy.
Then along came those pesky rainbow tables. Suddenly, huge collections of passwords could be hashed and stored in these colourful little tables then compared to existing hashed passwords (often breached from other people’s databases) at an amazing rate of knots thus disclosing the original plain text version. Bugger.
So we started seasoning our passwords with salt. Adding random bytes to the password before it was hashed introduced unpredictability which was the kryptonite to the rainbow table’s use of pre-computed hashes. Suddenly, those nice tables of hashes for passwords of common structure became useless because the salted hash was entirely uncommon.
But now there’s an all new threat which has turned the tables on the salted hash – Moore’s law. Of course Moore’s law in itself is not new, it’s just that it has been effected on computer processing power to the point that what was once a very computationally high bar – the manual computing of vast numbers of hashes – is now rapidly becoming a very low bar. Worst of all, it’s leaving our hashed passwords vulnerable to the point that many existing accepted practices make salting and hashing next to useless.
A quick hashing recap
Let’s take a quick step back before talking about what’s wrong with the hashing algorithms of today. The problem that cryptographic storage of passwords is trying to address is to limit the potential damage of unintended disclosure of passwords in storage. Now of course all the good upstream security practices such as mitigating against SQL injection vulnerabilities and protecting your backups still apply, this is about what happens once things go really, really wrong.
We were reminded of this just the other day when WHMCS was breached and thousands of account details were leaked. In this case it appears that some basic social engineering was used to circumvent the host’s security thus allowing access to the database of user accounts. It was a similar story with LinkedIn just a little bit later when 6 million passwords were exposed through (as yet) unknown or undisclosed means. Disclosure of passwords in storage happens. Lots.
So this is really the whole point of hashing – once you get owned to the extent that WHMCS and LinkedIn were, secure cryptographic storage of the passwords is the only thing saving your customer’s credentials. And remember, a large percentage of these credentials will be reused across other services so secure storage is about protecting a lot more than just the site that was breached.
The trick is to ensure the effort to “break” the hashing exceeds the value that the perpetrators will gain by doing so. None of this is about being “unhackable”; it’s about making the difficulty of doing so not worth the effort. In this case when I say “break” or “crack”, I’m talking about re-computing hashes rather than finding weaknesses in the algorithms themselves. I’m literally talking about taking a plain text string, hashing it then comparing it to a password already in storage. If they match, then I’ve just discovered the plain text password.
A quick password practices recap
First things first – we suck at choosing passwords. Big time. When I analysed one of the Sony breaches last year, I found a number of pretty shoddy practices:
- 93% were between 6 and 10 characters long
- 45% were comprised entirely of lowercase characters
- 36% were found in a common password dictionary
- 67% were reused by the same person on a totally unrelated service (Gawker)
- Only 1% of them contained a non-alphanumeric character
What this means is that in the scale of potential passwords – that is using all the characters available and making them as long and as unique as desired – passwords conform to very, very predictable patterns. In fact you only need to take a highly constrained range (such as 6 to 8 character lowercase) and you’re going to cover a significant number of passwords. Or alternatively, you take a list of common passwords in a password “dictionary” and you’re going to have a similar result. More on that shortly.
The ASP.NET membership provider
I’ve been a proponent of the ASP.NET membership provider for a number of reasons:
- It’s extremely easy to build registration, logon and account management facilities on top of.
- The Visual Studio templates for ASP.NET websites have a lot of this functionality already built in.
- The underlying database and data access is auto-generated saving a lot of manual “boilerplate” coding.
- The password storage mechanism defaults to a “secure” salted SHA1 hash.
The first three points are still very relevant, the last one, not so much. Let’s take a look under the covers.
Firstly, let’s look at the salt. This is a 16 byte cryptographically random string generated by RNGCryptoServiceProvider then Base64 encoded:
private string GenerateSalt()
{
byte[] data = new byte[0x10];
new RNGCryptoServiceProvider().GetBytes(data);
return Convert.ToBase64String(data);
}
The salt is then passed off to the EncodePassword method along with the password and the format we’d like to store the password in (we’re just assuming SHA1 for the moment). This method is a bit lengthy but I’m going to include it all because I know some people will like to pick it apart:
private string EncodePassword(string pass, int passwordFormat, string salt)
{
if (passwordFormat == 0)
{
return pass;
}
byte[] bytes = Encoding.Unicode.GetBytes(pass);
byte[] src = Convert.FromBase64String(salt);
byte[] inArray = null;
if (passwordFormat == 1)
{
HashAlgorithm hashAlgorithm = this.GetHashAlgorithm();
if (hashAlgorithm is KeyedHashAlgorithm)
{
KeyedHashAlgorithm algorithm2 = (KeyedHashAlgorithm)hashAlgorithm;
if (algorithm2.Key.Length == src.Length)
{
algorithm2.Key = src;
}
else if (algorithm2.Key.Length < src.Length)
{
byte[] dst = new byte[algorithm2.Key.Length];
Buffer.BlockCopy(src, 0, dst, 0, dst.Length);
algorithm2.Key = dst;
}
else
{
int num2;
byte[] buffer5 = new byte[algorithm2.Key.Length];
for (int i = 0; i < buffer5.Length; i += num2)
{
num2 = Math.Min(src.Length, buffer5.Length - i);
Buffer.BlockCopy(src, 0, buffer5, i, num2);
}
algorithm2.Key = buffer5;
}
inArray = algorithm2.ComputeHash(bytes);
}
else
{
byte[] buffer6 = new byte[src.Length + bytes.Length];
Buffer.BlockCopy(src, 0, buffer6, 0, src.Length);
Buffer.BlockCopy(bytes, 0, buffer6, src.Length, bytes.Length);
inArray = hashAlgorithm.ComputeHash(buffer6);
}
}
else
{
byte[] buffer7 = new byte[src.Length + bytes.Length];
Buffer.BlockCopy(src, 0, buffer7, 0, src.Length);
Buffer.BlockCopy(bytes, 0, buffer7, src.Length, bytes.Length);
inArray = this.EncryptPassword(buffer7,
this._LegacyPasswordCompatibilityMode);
}
return Convert.ToBase64String(inArray);
}
Notice that before the password is hashed, the salt is Base64 decoded (line 8 above) so when you see the salt in the database you need to remember that it’s not the string that was used in the actual salting process. For example, when we see the salt "AB1ZYgDjTR4alp4jYq4XoA==", that’s the encoded value of the source bytes. The hashed password itself is also Base64 encoded before being stored in the data layer.
Cracking at the speed of GPUs
This is an AMD Radeon HD 7970:

It’s a high-end consumer graphics card that retails for about $500 in Australia. I bought one the other day in part to drive more screens than my old one permitted and in part to understand more about what goes into cracking hashes. This is where hashcat comes in. You see, using hashcat to leverage the power of the GPU in the 7970 you can generate up to 4.7393 billion hashes per second. That’s right, billion as in b for “bloody fast”.
Different hashing algorithms execute at different speeds and that’s a key concept for this article. The 4.7B mark is for MD5 which is considered antiquated. The SHA variants are generally preferred (as is the case in the membership provider) and the speed for SHA1 drops down to a “mere” 2.2B hashes per second.
What it means is simply this: if you have the salt and you have the password hash, a fast GPU is going to let you generate new hashes using the salt and compare them to the existing hashed password at an extremely fast pace. Repeat this process enough times and eventually you’ll match the newly generated hash against the stored one thus “cracking” the password. Let’s have a go at that.
Creating a test environment
Let’s go back to that Sony password analysis I mentioned earlier. There were almost 40,000 plain text passwords in that breach (depending on how you de-dupe it) and what I’m going to do is use those to regenerate “secure” accounts using the ASP.NET membership provider. I’m doing this because I want to use realistic passwords in this demo so that we get a real idea of how this whole thing works.
I jumped into Visual Studio 2010 and created a brand new MVC 3 app running on .NET 4 then scripted the account creation based on the Sony passwords. How does this work? Simply by enumerating through the account creation logic:
foreach (var password in passwords)
{
MembershipCreateStatus createStatus;
Membership.CreateUser(
"user" + i, // User name
password.Password, // Password
"foo@bar.com", // Email
null, // Password question
null, // Password answer
true, // Is approved
null, // Provider key
out createStatus); // Status
i++;
}
Once this runs, here’s what we end up with in the database:
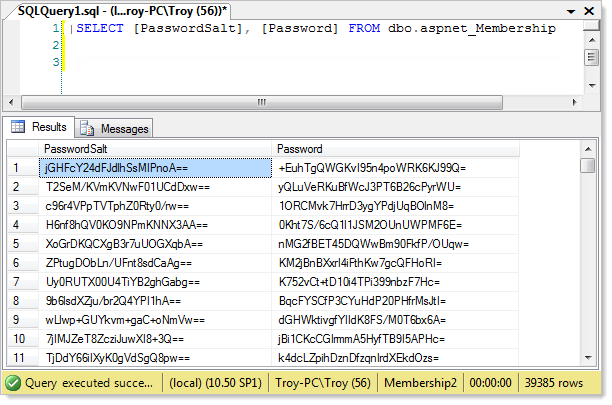
If you’re using the membership provider for any of your projects, you’ll have a structure that looks just like this in your database. The table name might appear differently as the newer templates in Visual Studio 2012 implement the web providers model for membership but it’s exactly the same database structure. It’s this storage mechanism that we’re now going to break.
The assumption we’re going to make is that this database has been breached. Of course we’ve adhered to all the good app development guidance in sources like the OWASP Top 10 but ultimately evil has overcome good and the hashes are out there in the wild.
In order to begin cracking those hashes we need to dump them into a format which hashcat understands. The way hashcat deals with hashes is that it defines a certain hash type and requires a hash list of a corresponding structure. In this case, we’re going to use the EPiServer pattern.
What’s EPiServer? EPiServer is a “content management, community and social media, commerce and communication” product but what’s important to us is that it sits on top of the ASP.NET membership provider (which probably would have been a more suitable title for hashcat to use).
The format we need to use involves four “columns” delimited by a star:
- The hash signature – “$episerver$”
- The version – it’s all “0” which implies SHA1
- The base64 encoded salt
- The base64 encoded hash
This is easy to dump out of SQL Server so that we end up with a text file called “MembershipAccounts.hash” which looks like this:
$episerver$*0*Z5+ghPUN6L8bVjdZFLlknQ==*dGOIcZDFNETO8cyY4i0BGcOD+mg=
$episerver$*0*detWsWTuzxI21nzefT6tNQ==*FbVX28Yaw5tPGj2sZUS38Cm5obk=
$episerver$*0*yZmUqUTKjod0TjBgS6y74w==*dWsNk9FEB8uAcPGhuzgKw+EdYF0=
$episerver$*0*heFEX9ej5vTa9G7X5QB8Fw==*TR2abu7N2xxqXxleggRXIBuqhr8=
$episerver$*0*xffmFD4ynyLnMkdzvbvuLw==*+1aODh+RowjblZupczhVuZzkmvk=
$episerver$*0*e++8ztWilfow0nli7Tk2PA==*acTusUU8a11uSaKbr/EKo7NNFNk=
$episerver$*0*qjAbSa51wjAxxBIVYu98Rg==*YIFas6OtzjQ3aKoOelIBjA9BvNM=
...
So that’s the hashes ready to go, now we just need to work out how we’re going to crack them.
Dictionary based password cracking
When we talk about “cracking” hashes, we’re really just talking about regenerating them en masse and there are several ways we can do this. The simple yet laborious way is to just work through a character set and range, for example lowercase letters only between 6 and 9 characters. This would actually cover 82% of the Sony passwords but would result in 104,459,430,739,968 possibilities (that’d be 104 trillion) so even at GPU speeds you’re looking at hours per password as each one needs to be attacked uniquely due to the salt. It would mean doing this:
SHA1(salt + “aaaaaa”)
SHA1(salt + “aaaaab”)
SHA1(salt + “aaaaac”)
…
All the way up to 9 chars and all the way through the lowercase alphabet. But this isn’t how people create passwords – it’s way too random. Of course random is how people should create passwords – but they don’t. The reality is that most people conform to far more predictable password patterns; in fact they’re so predictable that we have password “dictionaries”.
This is not your Oxford or your Webster, rather a password dictionary is a collection of commonly used passwords often collated from previous breaches. Of course this is not exhaustive – but it’s enough.
“Enough” is a very important concept when we talk about cracking passwords; it’s not necessarily about exhaustively breaking every single one of them and resolving to plain text, it’s about having sufficient success to justify the objective. Of course the objective will differ between evildoers, but the question for us as developers and app owners is “how much is enough?” I mean how much is enough to leave us in a very sticky position (even more so than the fact our data was breached in the first place)? A quarter of them? Half of them? Maybe just one of them?
Getting back to dictionaries, the objective when cracking passwords is to use a dictionary that’s extensive enough to yield a good harvest but not so extensive that it’s too time consuming. Remember, when we’re talking about salted hashes then every single record needs to get assessed against the dictionary so when we have large volumes of passwords this can become a very time consuming exercise.
The dictionary I chose for this exercise is one from InsidePro appropriately called hashkiller (actually, they call it hashkiller.com but there doesn’t appear to be anything on that URL). This is a 241MB file containing 23,685,601 “words” in plain text, just one per line. Why the quotes around “words”? Because it contains things like “!!! $ @@@” (spaces in there are as found), “!!!!!!888888” and “!!!!!!!#@#####”. It also contains 5,144 variations of the word “boob” (yes – I checked) so as you can see, it’s not short on variety.
Cracking
The cracking process is very simple; you have two inputs which are the list of salts with hashes and then there’s the password dictionary. These are passed into the hashcat command with a parameter to indicate the type of hashes we’re dealing with which is the EPiServer format (“-m 141”). Here’s how the command looks:
oclHashcat-plus64.exe -m 141 MembershipAccounts.hash hashkiller.com.dic
I want to try and give a sense of how fast this process executes so I compiled the beginning and end into a short narrated video (it’s summarised further on if you want to skip through):
Impressive? Quite, but also a bit scary. Let’s take a closer look at the summary after everything has run:
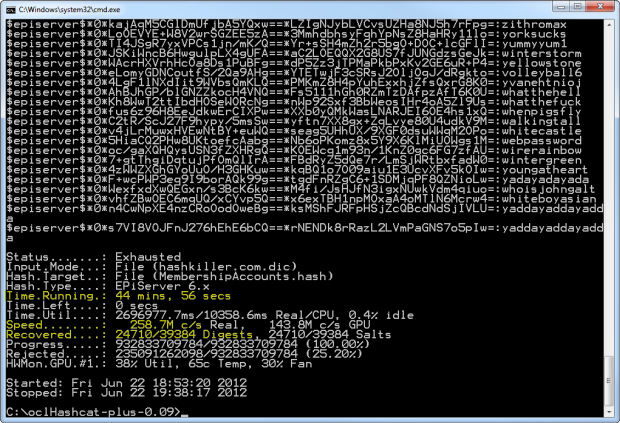
What we once considered “secure” – that is salted SHA hashes – has just been obliterated. In fact in the time it takes to watch a couple of episodes of the Family Guy, we cracked 24,710 hashes or 63% of the total sample size. The remaining 37% just simply weren’t in the password dictionary but a larger dictionary and perhaps sitting through the Lord of The Rings trilogy and the rate of success would be a lot higher. The point is that this is a trivial amount of time to spend in breaking a significant proportion of the hashes.
What’s more, there are passwords in there which many would consider to be “strong”. How about “volleyball6” – 11 chars of two different types. Further up the list was “zaq1@WSX” – 8 chars of upper, lower numeric and symbol, surely enough to pass most security policies yet even when stored as a “secure” salted hash, utterly useless.
All of these cracked passwords have now been saved to a file called “hashcat.pot”. Here’s what’s inside:
$episerver$*0*v4jLrMuwxHVEwNtBY+euWQ==*seag5UHhUX/9XGF0dsuWWqM2OPo=:whitecastle
$episerver$*0*5HiaCQ2PHw8UKtoefcAabg==*Nb6oPKomz8x5Y9X6KlMiUOWgs1M=:webpassword
$episerver$*0*oc/gaXQHQysUSN3fZXHRgQ==*KOEWcq1m93n/1KnZ0gc6FG7zfAU=:wirerainbow
$episerver$*0*7+gtThgiDqtujPfOmQlIrA==*FBdRyZ5dQe7r/LmSjWRtbxfadW0=:wintergreen
$episerver$*0*4zWWZXGhGYoUuO/H3GHKuw==*kqBQ1o7O09aiu1E3UcvXFv5kOIw=:youngatheart
$episerver$*0*F+wcPWP3eq9I9borAQk99g==*tgdFnRZgC6+1SDMjqPF8QZNioLw=:yadayadayada
$episerver$*0*WexfxdXwQEGxn/s3BcK6kw==*M4fi/JsHJfN3igxNUwkVdm4qiuo=:whoisjohngalt
$episerver$*0*vhfZBwOEC6mqUQ/xCYvp5Q==*x6exTBH1npMOxaA4oMTlN6Mcrw4=:whiteboyasian
$episerver$*0*n4CwNpXE4nzCRoOodOweBg==*ksMShFJRFpHSjZcQBcdNdSjIVLU=:yaddayaddayadda
$episerver$*0*s7VI8VOJFnJ276hEhE6bCQ==*rNENDk8rRazL2LVmPaGNS7o5pIw=:yaddayaddayadda
This is pretty much just the list of source hashes with the plain text password appended to the end. In most instances where accounts have been breached, the exposed hashes and salts will sit alongside the user name and email addresses so armed with the info above it’s simple to join everything back up together.
One more thing before we move on; did you notice the speed of the cracking was “only” 258.7M per second? What happened to the theoretical throughput of a couple of billion SHA1 hashes per second? The problem is that the higher throughput can only be achieved with “mutations” of the password dictionary values or by working through different password possibilities directly within the GPU. In other words, if you let the GPU take a dictionary value then transform it into a number of different possibilities it can work a lot faster. The GPU can’t be fed passwords fast enough to achieve the same level of throughput so effectively having a list of passwords is bottleneck.
You can actually observe the GPU only working at about half its potential; here’s what the MSI Afterburner Hardware Monitor had to say about the 7970 just working directly through the dictionary on the left versus applying mutations to the dictionary on the right:
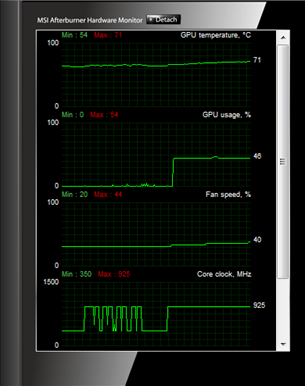
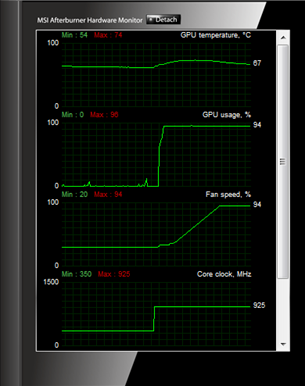
See the GPU usage % in the second graphs? When the 7970 starts approaching that maximum utilisation and the fan ramps up it all starts to sound a bit jet-engine-at-max-thrust. But ultimately, whilst the rate of direct dictionary hashing may be lower, the accuracy is significantly higher and the time to produce meaningful results is more favourable.
How do we fix this?
So that’s the bad news – your salted SHA hashes are near useless against the bulk of passwords users typically create. The ASP.NET membership provider now provides little more than a thin veneer of password security in storage. And don’t think you can fix this by going to SHA256 as implemented in System.Web.Providers, it’s barely any better than SHA1 in terms of the rate at which you create hashes. We need a better mousetrap.
Here’s the problem:

The membership provider hashes were cracked because it’s just too damn fast to regenerate them. This might sound sacrilegious in a world where we developers go to great lengths to eke out every last skerrick of performance at every point possible, but fast hashes are killing our security.
But let’s get a bit of context here – do we really need to be able to generate 4.7 billion password hashes per second? That’s like taking the entire Facebook population of over 900 million and sequentially hashing every single password 5 times every second. And that’s on consumer hardware. No, we don’t need to get anywhere even close to that.
The problem is that algorithms like MD5 and SHA were designed to demonstrate data integrity at high computational speed rather than to provide a password storage mechanism; cryptographic hash functions are not password hash functions. Even if they were “safe” for password storage when designed, MD5 goes back 20 years now so by Moore’s Law we now have processors that are now eight thousand times faster.
There are various approaches for breathing life back into old algorithms; key stretching, for example, where an algorithm which is too fast is “slowed” by repeating it over and over again, perhaps thousands of times. But the guidance around the likes of MD5 and SHA is clear and OWASP summarises it quite succinctly:
General hashing algorithms (eg, MD5, SHA-1/256/512) are not recommended for password storage. Instead an algorithm specifically designed for the purpose should be used.
What we need is a hashing algorithm which was designed from the ground up with speed in mind, not fast speed, but slow speed.
Edit: I was a little vague here and several people have called me on it. The concept of increasing the effort required to execute the hash function is one that is frequently implemented by key stretching and indeed this is modus operandi of PBKDF2. In fact PBKDF2 may then be applied to an algorithm such as SHA so strictly speaking, SHA is still being used, just not as we know it in its single iteration form. It then becomes a question of how many iterations are enough which I talk about a little further down.
There are numerous hashing algorithms designed to do this: bcrypt, PBKDF2 just to name a couple. The problem is that support for these differs between frameworks and their level of deep integration with features such as the ASP.NET membership provider is often either non-existent or a second class citizen to their faster cousins. But the thing about algorithms like these is that they’re adaptive:
Over time it can be made slower and slower so it remains resistant to specific brute-force search attacks against the hash and the salt.
Clearly the ability to increase the workload is important if we don’t want to be caught by Moore’s law again in the near future. All we need is a way to integrate this into our existing work.
“Fixing” ASP.NET password hashing
Fortunately there are a number of solutions available to implement stronger hashing algorithms in ASP.NET. For a start, there’s Zetetic’s implementation of bcrypt and PBKDF2 for the membership provider. The neat thing about this approach is that you can drop it directly into your existing app from NuGet:
Zetetic makes use of bcrypt.net so you could always just go and grab that one directly if you didn’t want to implement the entire membership provider. Unfortunately there is one major drawback with Zetetic’s implementation – it requires GAC installation and machine.config modification. This is unfortunate as it rules out many hosted environments such as I use for ASafaWeb with AppHarbor. I can deploy almost anything I like in the app but there’s no way I can get anywhere near the GAC or machine.config in a shared environment.
Then there are implementations like CryptSharp from Chris McKee which make it extremely simple to implement bcrypt and PBKDF2 along with others such as SCrypt and Blowfish. There’s no direct membership provider integration, but then there’s also no GAC or machine.config dependency.
Some debate does go on about which of the slower algorithms are the right approach. For example, which ones are endorsed by NIST – and does it even matter? There’s a whole world of pros and cons, ups and downs but the one thing that’s universally agreed on is that MD5 and SHA are now simply not secure enough for password storage.
The impact of slow hashes on speed (and CPU overhead)
Slowing down hashing might be just fine for security, but what other adverse impact might it have? Well for one, the logon process is going to be slower. But let’s be pragmatic about this – if an exercise which should happen no more than once per session at the other end of all that network latency and browser rendering time adds, say, 200ms to the process, does it matter? Most will argue “no” – it’s an indiscernible amount of time of negligible increase to the existing user wait time and it’s added to an infrequent process.
But what about the overhead on the server itself? I mean are slower hashing algorithms sufficiently computationally expensive to have an adverse resource impact to the point where it’s going to cost money for more resources? Some say “yes”, it’s a concern and that with enough simultaneous hashing going on it’s going to have seriously negative impact. In this example, 100 simultaneous threads consumed 95% of the CPU resources for 38 seconds so clearly this is a problem.
I would love to have this problem! Imagine the scale you need to reach to have 100 discrete individuals simultaneously attempting to hash a password via logon, registration or password change on a frequent basis – what a glorious problem to have! To reach a scale where slow hashing has that sort of impact – or even only 10% of those numbers – you’re talking about a seriously large app. Consider a single logon per session, use of the “remember me” function (rightly or wrongly), frequency of use then juxtapose that with a process that even when deliberately slow is probably somewhere in the 100ms range. But of course with an adaptive hash algorithm like bcrypt it doesn’t have to be 100ms, it can be half that, or double that or whatever you decide is the right balance of speed versus security risk on the hardware you’re running today. Let’s be clear that this is definitely something to consider, it’s just not something that many of us need to worry about.
Part of the problem is that when we apply hashing for the purposes of password storage we’re doing so on the CPU – which is slow – but then when someone attempts to crack it they’re doing so on the GPU – which is fast. Creating higher workload might apply equally across both processing units but it hurts the one intended for legitimate hashing far more than it hurts the one frequently used for nefarious purposes. It just ain’t fair!
One school of thought is to leverage GPU hashing on the server to effectively level the playing field. If the CPU is genuinely 150 times slower to hash passwords then wouldn’t it make sense to move this process to the GPU then just ratchet up the workload to an acceptable limit? This could well be the perfect solution although of course you need to have the hardware available (and you’re not going to find fast GPUs already in most servers) plus the code responsible for the hashing needs to target the GPU which certainly isn’t the default position for most server-based hashing implementations.
But it did have me a bit intrigued; what really is the impact of employing slow hashing in a live environment? And is there much difference in speed between the SHA variants and bcrypt, or even MD5 for that matter? So I built a demo to help give some context and put it up here: https://asafaweb.com/HashSpeed
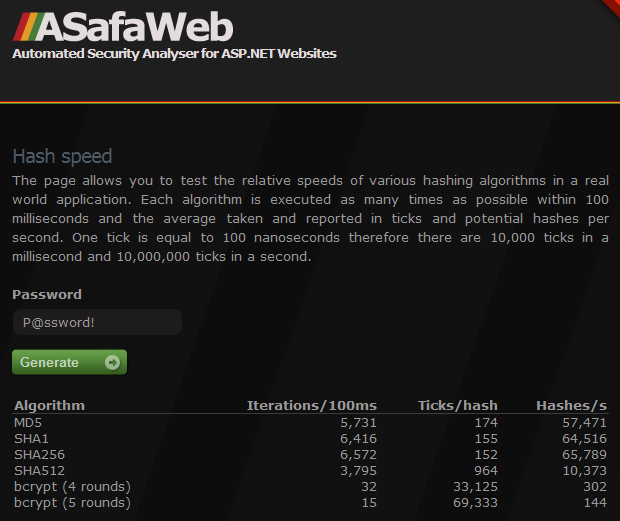
This is not a high-volume site, in fact it’s very low volume but it does run in AppHarbor’s public cloud and therefore shares resources with all sorts of other apps. As such, the speed is inconsistent plus it’s dependent on the Stopwatch class which can be erratic (incidentally, the results were far more stable in my local environment and also significantly faster).
There are a few lessons to take away from this:
- Relatively speaking, the speed of SHA1 and SHA256 is close to each either and even close to MD5 – about a 15% variation at most.
- SHA512 may appear quite a bit slower but is still way too fast for hashing passwords (hashcat claims 73 million per second in the 7970 GPU).
- There is a massive difference between the MD5 and SHA variants as compared to bcrypt with even a small number of rounds (bcrypt.net defaults to 10 which 32 times slower than with 5 rounds).
When you can tune the processing overhead of the hashing algorithm there’s really not much of an argument to make in terms of it adding unacceptable overhead to the environment. Too slow? Speed it up. It’s not like you’re going to get all the way down to SHA based speeds anyway; there should never be a case for sub-millisecond password hashing as demonstrated in the example above.
Forget the generic password strength guidance
One thing I’ve always found a bit amusing – particularly in light of the cracking exercise earlier on – is guidance along the lines of “It will take X number of days / weeks / months to crack a particular password. Let me demonstrate with the password “00455455mb17” using the Passfault website:

Well that oughta do it! The problem is that we just cracked it in 45 minutes. Actually, more accurately, we cracked this one and 24,709 others as well but let’s not split hairs. Password selection (and more specifically, cracking) is not subject to the mere rules of entropy, no, uniqueness is absolutely essential to protecting them and conversely predictability is a key part of cracking them.
Finally, some practical advice
So what can we conclude from this exercise? Let me summarise:
Salted SHA is near useless: Sorry to be the bearer of bad news (actually, one of many bearers), but the ease, speed and price with which salted SHA can be cracked for the vast majority of passwords is just too simple.
Use an adaptive hashing algorithm: You have numerous options, some of which have been discussed here. Choose one – with appropriate care.
Strike a balance between speed and performance: Slower algorithms increase computing overhead so tailor the work factor to suit both the capability of the infrastructure and the volume of the audience.
But after all this talk of GPUs and algorithms and hash speeds there’s one really, really simple solution that will take you 60 seconds to implement and will make your passwords near uncrackable. It’s this:
<add name="AspNetSqlMembershipProvider" minRequiredPasswordLength="30"
minRequiredNonalphanumericCharacters="5" />
That’s it – increase the length and complexity requirements to the point that it’s highly likely any chosen passwords will be unique, not to mention outside the range of most default cracking patterns. Of course unfortunately, nobody in their right mind is going to demand this degree of complexity because most users don’t have a means of tracking unmemorable passwords. It’s a shame though because that’s pretty much all our cracking problems solved right there.
But let me wrap this up with the following quote from the preface of Bruce Schneier’s Applied Cryptography:
There are two kinds of cryptography in this world: cryptography that will stop your kid sister from reading your files, and cryptography that will stop major governments from reading your files.
This does indeed appear to be the case and unfortunately SHA is now firmly in the former category.
Resources
- Are you sure SHA-1+salt is enough for passwords?
- Speed Hashing
- Do any security experts recommend bcrypt for password storage?
- How To Safely Store A Password
- Storing Passwords Securely
- Towards more secure password hashing in ASP.NET