The other day, my blog went down:
Sorry folks, blog is down for a bit while @TryGhost puts out the fire pic.twitter.com/h3YAUc2gp0
— Troy Hunt (@troyhunt) September 15, 2016
Now clearly I don't like my blog going down but hey, this is technology and sometimes it fails us. But I host my blog on Ghost Pro which means that when it goes down, I do this:

Wait - aren't I meant to be running around fixing things?! Well no, that's the responsibility of the platform provider and whilst I'd obviously prefer the blog was up and running, it's not my responsibility. So I had a swim while others dealt with the problem.
Now I knew how to handle this emergency because I'd had practice in the past. It was down a few months earlier too:
@Nin_99 @GregF it's @TryGhost that's down pic.twitter.com/wCqpnFgW9z
— Troy Hunt (@troyhunt) July 26, 2016
Clearly I had to do something about this, so I headed off to deal with the problem:

By no means do I want to suggest Ghost Pro has any inherent reliability problems though, I've seen outages in my SQL Azure database that sits behind Have I been pwned (HIBP) too:
And on the day my Azure @pluralsight course goes live :( Looks like @haveibeenpwned has been down for hours pic.twitter.com/3aUsQbtM7G
— Troy Hunt (@troyhunt) April 3, 2015
On that occasion, some more action was required:

So I went tubing with the kids.
This is clearly all a bit tongue in cheek, but here's the point: by using managed platforms like Ghost Pro and Azure's PaaS (platform as a service) offerings, outages are other people's problems. That doesn't mean they won't happen (clearly), but when these services go down I know that the best people in the business are dealing with the outage and doing a better of job of it than what I could self-managing the thing. That's almost certainly the case for you too: you might be the world's greatest sys admin but when you're managing your blog on a VPS somewhere and then you go to sleep, you're going to have problems.
All of this is why I'm such a big proponent of pushing everything as far as possible to the right on this chart:
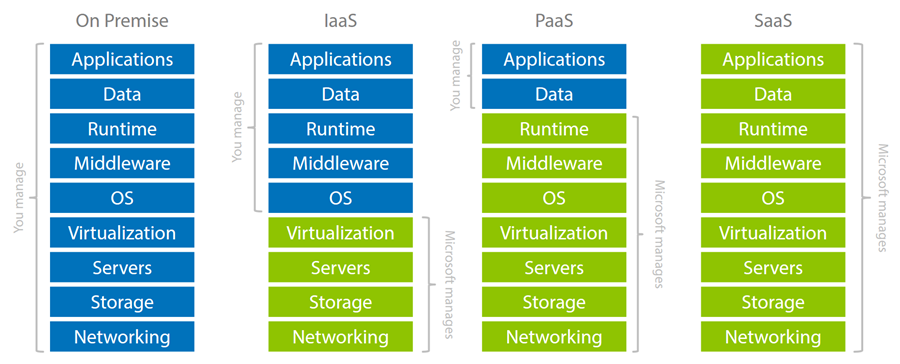
HIBP runs primarily on PaaS. I load the application into Azure's App Service (effectively just a website) and the data into their managed SQL offering. I do actually use some IaaS (infrastructure as a service) as well for data breach processing but only because I need more ability to run things on the OS.
This blog, on the other hand, runs on Ghost Pro which is SaaS (software as a service). The service they provide is the Ghost blogging platform where they manage everything for me:
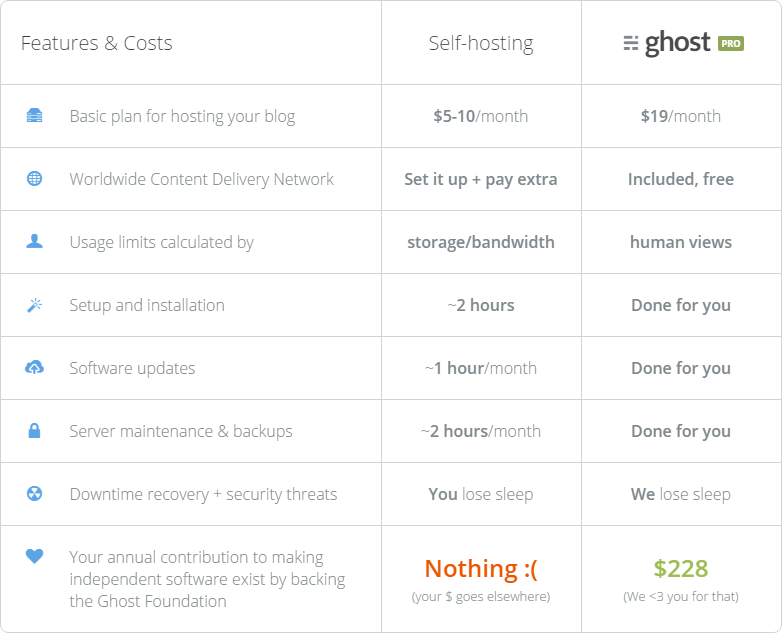
The downtime and recovery line is a perfect illustration of what I'm talking about above and I cover this in more detail in the launch post for this new blog earlier this year. Of course this doesn't guarantee you of no outages as the tweets above clearly demonstrate, but what it does is ensures that someone else is looking after it all for me. Even though I've had a couple of outages this year, if you add them all up and look at the availability of either HIBP or this blog, you're going to be looking at 99.9x% availability which for these classes of site, I'm quite happy with.
Another great illustration of why you want to "push to the right" on that earlier diagram is the piece I wrote on vBulletin in August. Here we have troves and troves of self-managed bulletin board systems that never get maintained, fall out of date patch wise and get pwned left right and centre. There are few better illustrations of why you want to task someone else with managing your things than this.
By all means, self-manage your things, but while you're putting out the fires I'm going to be doing something else productive, like laying in the pool :)