Earlier today I asked the question I know it's a bit of a religious debate, but control name prefixes (txt, lbl); useful practice or the devil's work? and was a little surprised by the result. Actually, what surprised me was the unanimous “devil’s work” response when I expected some balanced arguments!
What am I talking about? I’m talking about names that look like this:
<asp:Label runat="server" ID="lblFirstName" /> <asp:TextBox runat="server" ID="txtFirstName" />
And why am I talking about it? Because FxCop doesn’t like it very much:
The individual words that make up an identifier should not be abbreviated and should be spelled correctly.
Microsoft goes into more detail in rule CA1704 but the bottom line is simply that they believe names should be spelled correctly and abbreviations kind of play havoc with that.
The argument “for”
Most of the arguments in favour of control prefixes centre around improved intellisense. The argument goes something like “It’s faster because as soon as I start typing the control prefix my list is filtered down to that control type”. The prefix brigade wants to see something like this:

Not having the prefix means the initial intellisense on the few characters picks up all sorts of other names:
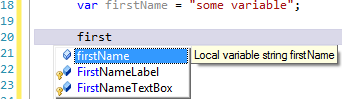
Thing is though, we’ve now got Pascal case intellisense in Visual Studio which means we can do this:

Frankly, this is even more explicit than the first version as we’re not going to get every single text box control in the list. It’s both succinct and explicit. Ok, you need to adjust your way of working a little bit but the advantages go way beyond just control references.
But what about when you want to find all the controls of a particular type on a page? Does having the ID of every text box on the page beginning with “txt” help? Let’s try it with a natural language suffix:

So no, you’re not gaining an advantage on that front. In fact so long as there is some form of consistency in control naming, it really doesn’t matter whether it’s an abbreviated prefix or a natural language suffix.
For the record, all these screen grabs are using ReSharper’s intellisense but the native Visual Studio 2010 intellisense is equally capable in these scenarios.
The argument “against”
Well there’s obviously the fact that FxCop doesn’t like it, but I’ll come back to that in the next section. Let’s start with a slightly more pragmatic basis.
The first thing is that abbreviated control prefixes is not “a” standard, it’s actually two standards. There’s agreeing that everyone is going to apply a prefix then there needs to be a standard on what prefixes to use when. It’s no good if John likes “val” for his required field validator and Jane likes “req” for hers, they’ve got to come to an agreement and create a standard on how the standard needs to be implemented! It’s a bit like having a policy on policies (don’t laugh, they exist).
Your other problem is that you can’t spell check them so any automated static code analysis which can check spelling (of which FxCop is obviously one), is not going to be very happy. Yes, you can usually implement exceptions to rules or customise dictionaries but you’re on a slippery slope here and its one more thing you’re going to need to maintain. Introduce a new control; that’ll be another exception. By the by, spell checking of names in code is a great idea because it’s simply so easy so screw it up in this spell-check dependent age (I assume it’s not just me!) and then so easy to proliferate it via intellisense.
The “standard standards” argument
One thing I really like about FxCop standards (and StyleCop standards as well, for that matter), is that they’re not mine. It’s not Troy’s interpretation of what’s right and wrong, it’s not the interpretation of the organisation I work on software for, they’ve been defined by the guys who built the framework we’re all working with.
This doesn’t make them right, and it doesn’t need to. What it does do is makes them very broadly relevant. That’s the whole thing about naming standards, it’s not that Pascal case is right and camel case is wrong or that underscore word breakers are evil, it’s simply that everyone who follows the standard agrees to do it the same way. Americans like to drive on the wrong side of the road but it works just fine for them because everybody does it :)
In my day job I work with a lot of totally independent software vendors and the last thing I want to do is dictate minor details about how to name a variable. What I want to do is say “There – go and follow what those guys say”, and when those guys are Microsoft and they provide the (free) tooling to analyse compliance, it’s a really easy decision to make.
Summary
I’ll admit I’ve switched backwards and forwards between many different naming standards over the years, usually depending on the environment and the people I’m working with. I really don’t have a preference for any one particular pattern of naming, but what I do have a preference for is the ease and consistency with which people can apply it. Today that’s natural language, dictionary compliant names checked by FxCop, tomorrow it might be something different.
The final thought on all this is that standards are never static. The Pascal case intellisense example is a perfect illustration of how the rationale of today may be invalidated by the environmental changes of tomorrow. This is perfectly illustrated in Pete Brown’s post about .net Naming Conventions and Programming Standards - Best Practices where he originally extols the virtues of control prefixing in 2002 but revises to the contrary in 2009. I’m not advocating changing standards every day, Pete’s example is a 7 year gap between drinks which isn’t exactly a radical change to the way of working.
So do what’s right for today, but make sure “right” isn’t based on shaky grounds or spurious arguments and that most importantly, compliance is readily measurable and achievable. And acknowledge you may need to change it in the future, quite possibly in less than 7 years from now!