Let me make it crystal clear in the opening paragraph: this incident is not about any sort of security vulnerability on GitHub's behalf, rather it relates to a trove of data from their site which was inappropriately scraped and then inadvertently exposed due to a vulnerability in another service. My data. Probably your data if you're in the software industry. Millions of people's data.
On Saturday, a character in the data trading scene popped up and sent me a 594MB file called geekedin.net_mirror_20160815.7z. It was allegedly a MongoDB backup from August belonging to a site I'd not heard of before, one called GeekedIn (link to the original site removed after it started returning shady content, the original is in the filename at the start of this para) and they apparently do this:

A bit of searching around suggested that they're based just outside Barcelona and appear to be ramping up a service for recruiting technology professionals. A bit more searching around showed a couple of MongoDB instances running in Poland:
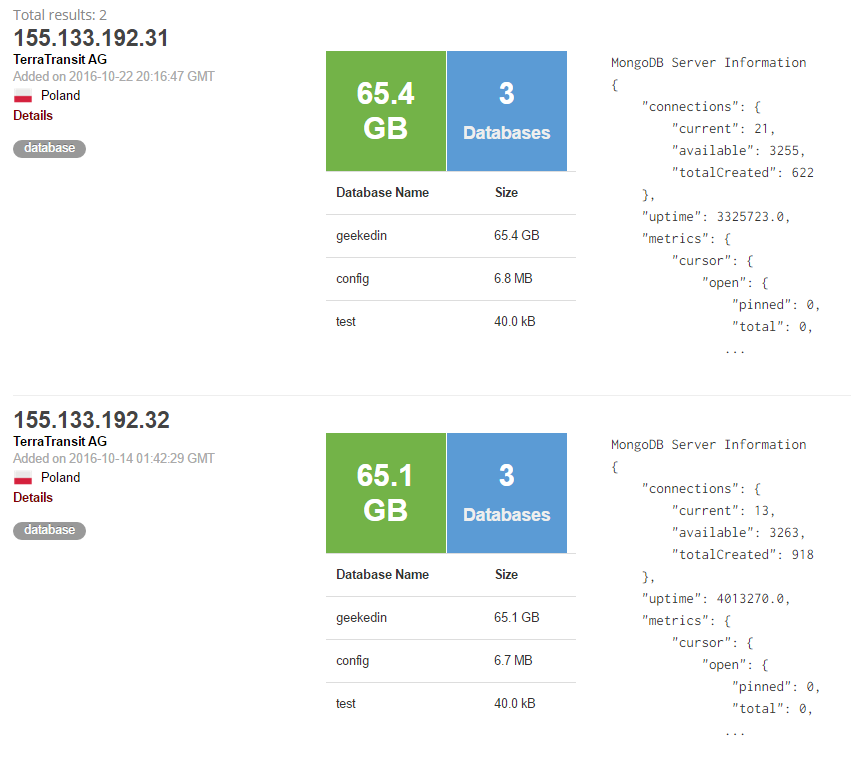
The second IP address there is the one the website itself is presently running on so all the dots are starting to join up. But it wasn't until I found my own data that the penny dropped on what was going on. Here's what I found:
{
"_id": "5cb692d1-8fd5-44d7-8639-e680fb2b30f41454836589580",
"_class": "com.geekedin.domain.entities.mongo.EDeveloper",
"scores": [],
"libraryScores": [],
"compactLibraries": [],
"name": "Troy Hunt",
"email": "troyhunt@hotmail.com",
"location": "Sydney",
"country": "AU",
"city": "0fab4eb2-c5d5-459d-a7c5-c50b845c12da1448621413411",
"score": 0,
"scanCompleted": false,
"socialNetworks": [
{
"_id": "https://github.com/troyhunt",
"socialNetwork": "other",
"url": "https://github.com/troyhunt"
},
{
"_id": "troyhunt",
"socialNetwork": "github",
"url": "https://github.com/troyhunt"
},
{
"_id": "http://troyhunt.com",
"socialNetwork": "other",
"url": "http://troyhunt.com"
}
],
"locationPoint": {
"x": 151.20732,
"y": -33.86785
},
"yearsOfExperience": 0,
"otherLocations": [],
"extraEmails": [],
"locateTryFailed": false,
"locateTried": true,
"beingLocated": false,
"remoteLocateTried": true,
"blogFindTried": false,
"contactIsPossible": true,
"freelancer": false,
"compactLibrariesComputed": false,
"compactLibrariesBeingComputed": false,
"followersFound": false,
"emailAddresses": [
{
"email": "troyhunt@hotmail.com",
"type": "primary"
}
]
}
And there's the GitHub references. When I took a look at my publicly facing GitHub profile, I did indeed have my email address exposed as well as my location. But my profile is actually rather sparse when compared to ones like this:
{
"technology": "06405e50-a3b3-471d-a50d-17fc2cb4a9181448621393946",
"library": "56623985e4b0cab0586c4d09",
"score": 0,
"lastCompute": {
"sec": 1449279293,
"usec": 262000
},
"endorsements": 0,
"version": "0.3-SNAPSHOT"
},
{
"technology": "06405e50-a3b3-471d-a50d-17fc2cb4a9181448621393946",
"library": "56623e9ae4b0cab0586cb344",
"score": 0,
"lastCompute": {
"sec": 1449279293,
"usec": 262000
},
"endorsements": 0,
"version": "0.1"
},
{
"technology": "06405e50-a3b3-471d-a50d-17fc2cb4a9181448621393946",
"library": "56623ab1e4b0cab0586c64ab",
"score": 0,
"lastCompute": {
"sec": 1449279293,
"usec": 262000
},
"endorsements": 0,
"version": "1.0.0"
},
{
"technology": "06405e50-a3b3-471d-a50d-17fc2cb4a9181448621393946",
"library": "56623ee2e4b0cab0586cb624",
"score": 0,
"lastCompute": {
"sec": 1449279293,
"usec": 262000
},
"endorsements": 0,
"version": "0.2"
}...
This is just a small snapshot of a profile that is ultimately hundreds of times larger than my full one shown earlier. The data above exists as part of a much larger set within a "scores" collection, evidently as part of a profile of the user's technology use. I won't go into any more detail here because I am going to give you the ability to pull your own data shortly and you'll be able to see what's in there firsthand. The other reason I won't give any more detail on it here is that whilst this appeared to be data that was obtained from publicly facing GitHub profiles, it felt wrong to see it all aggregated together here like this. I wasn't aware of any implementation within GitHub that publicly exposed this information for the purpose of mass consumption (i.e. via an API), and frankly, by now it was starting to smell a bit bad...
Last thing before I start talking about disclosure: when I analysed the data set I found almost 8.2 million unique email addresses. That's about what I'd expect in terms of the number of accounts on GitHub, but there was a twist in that 7.1 million ended with ".xyzp.wzf". What I realised on closer analysis is that these represented all the GitHub accounts that had no publicly facing email address. For example, my mate Niall Merrigan's profile is bereft of an address so his email in the data set is represented as niallmerrigan@github.xyzp.wzf. Within that data set there were also 15k @bitbucket.xyzp.wzf addresses so although it made up only a tiny percentage of the overall data, clearly they were drawing from more than one source.
Moving on, given what I'd seen thus far I decided to reach out to GitHub directly as it was their data that was involved here, even if it was leaked from another service. GitHub has a great track record of handling security incidents, not just in terms of having had a lot of experience with them, but in the way in which they've dealt with them. There's been incidents like the 2013 brute force attack by 40k unique IP addresses and the (really rather creative) Chinese attacks linked to the Great Firewall. I got in touch with a contact there within hours of establishing what the data was and suggested that firstly, they probably want to think about whether or not GeekedIn's practices were considered acceptable use and secondly, if there was any messaging they wanted to communicate around this incident. My concern for them was that here was a very large amount of "GitHub data" (said in quotes because it is, but it didn't come from them), and I didn't want the source to be misrepresented. Particularly if data was circulating among traders, there was every chance people would start popping up and saying "hey, I've got the GitHub data breach".
The approach we ultimately took was that both GitHub and I have reached out directly to GeekedIn independently. It wasn't easy though - the Twitter account on their site looks dead and the contact form there appeared non-responsive. I attempted to find a contact via Twitter which didn't yield anything useful beyond pointing to details on their site and the antiliasoft.com website the copyright belongs to is returning a 404 from Google. Ultimately, I reached out to an email address on that same domain and got a response yesterday, acknowledging the incident and making a commitment to secure the data.
I asked GitHub for something I could share with this post and they provided me with the following:
Third parties frequently scrape public GitHub data for various reasons, such as research or archival purposes. We permit this type of scraping so long as any user's personal information is only used for the same purpose for which they gave that information to GitHub. Using scraped information for a commercial purpose violates our privacy statement and we do not condone this kind of use.
So it's pretty clear then that this isn't cool:

As someone in the data breach myself, I don't want my data being sold this way. And again, yes, you can go and pull this data publicly on a per-individual basis but the constant response I got from close confidants I shared this information with is that "it just feels wrong". And it is wrong, not just the scraping of GitHub in the first place in order to commercialise our information, but then subsequently losing it via a MongoDB with no password and now having it float around the web in data breach trading circles.
As of now, the data is searchable in HIBP. But this time I've done something just a little bit different and that's made the actual raw data available. Now I want to be cautious here because this is not something I normally do nor something I expect to do again any time soon. Normally there's no way I'd load source data into HIBP and I've been vocally critical of any service that does this precisely because breach services themselves can be pwned. Particularly any storing of plain text credentials is enormously reckless and unfortunately there are multiple services out there doing just this.
The difference here is twofold though: firstly, this is publicly exposed data. No, it shouldn't have been aggregated en masse and no, it definitely shouldn't have been leaked, but it is data that on a per-individual basis you can go and retrieve from anyone's GitHub profile. Secondly, a significant component of the audience in this incident are people that will understand what that big collection of JSON means and know how to interpret it. These are tech people - people just like me - and a collection of curly braces and JSON syntax is speaking their language.
There's a third reason as well and that's a bit of an exploratory exercise for me. I very frequently hear from people after they find themselves in a data breach that they want to know what information was exposed about them. I get this - they want to know exactly what anyone holding the data now knows - but it's not something I've ever done for the reasons explained above. This was an opportunity to do that without the risks involved with sensitive data and with an audience on my wavelength. I'm really curious to see how feedback on this goes and what (if any) value it poses to people.
Big caveat time: You can only see your own data and only if your real email address was in the dump. I know, we've established it's publicly facing data, but I still want to constrain it to the data owners themselves. The way I've done this is by using HIBP's existing notification service which already has a means of verifying email addresses. It works like this:
- Go to haveibeenpwned.com/NotifyMe
- Enter your email address and receive the confirmation email
- Click on the link in the email to verify your address
That last step then shows a page like this for me and for any one of the million plus people who had their actual email address leaked:

When I toggle the "show raw geekedin data" I get my record:
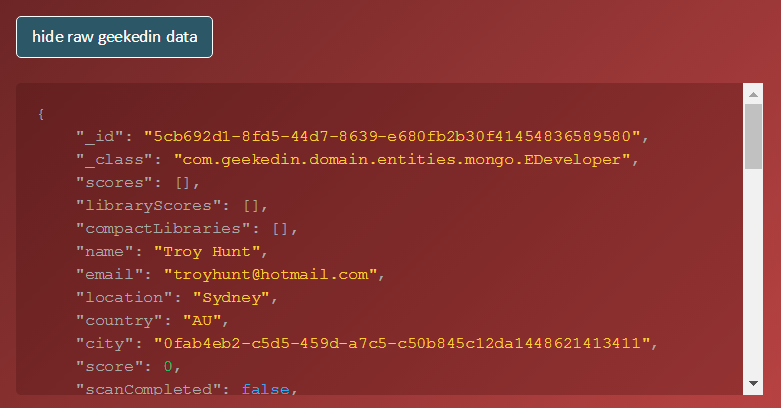
And that's it! Once again, you're only going to show up here if your email address was successfully pulled from GitHub, but I hope it's useful for the million plus people whose data was exposed somewhere they never expected it to be.