
Yesterday I wrote part 1 of this 2 part series and explained the Godzilla redundant approach of storage in Azure. Each bit of data you put into Azure storage gets replicated multiple times over within the same data centre so that you have redundancy against local failures (i.e. an unexpected Godzilla smash-and-grab). I also explained how it won’t save you from your own stupidity (or my own stupidity in the case I gave) and for that I configured automatic exports of SQL Azure to geo-redundant storage.
Now it’s time to tackle Azure Table Storage and Microsoft hasn’t given us any magic tricks within the Azure service offering so for that we need to head off to Red Gate.
Azure backup from Red Gate
I’ve written about Red Gate products on many a previous occasion and they tend to have this habit of taking an aspect of software development that’s difficult or tedious and somehow just making all the problems disappear in one fell swoop. For example, I can’t image not versioning my DB with SQL Source Control or orchestrating a database release on a CI server with anything other than SQL Compare and Data Compare or even just generating massive volumes of test data without SQL Data Generator. The stuff just works and it’s always awesome.
But all of that is just for SQL and we’ve solved the problems related to backing that up already in part one of this post, right? Well we’ve solved the SQL Azure versioning problem using the native export facility but I’ve still got 160 million rows of Azure Table Storage I’m rather fond of and so far, that only has Godzilla-protection, not Troy-just-did-something-stupid-and-dropped-the-table-protection. So here are Red Gate’s new shiny bits as they relate to Azure and how they solve the problem we’re facing here: say hello to Red Gate Cloud Services.
Now this service actually helps you address your Azure backup woes across a number of different data storage implementations, namely SQL Azure, SQL Server (remember, SQL ain’t SQL) and Azure Storage. I could have used the Red Gate service for the SQL Azure backup instead of going through the process above, but I really wanted to demonstrate what was already in the Azure box and you don’t have to go external to solve that problem. Backing up Azure Table Storage though, that’s a different issue.
Configuring the backup
Let’s jump into it and first up I’ve already created an account on cloudservices.red-gate.com and logged in. As soon as I’ve done that, here’s what I’m greeted with:

Ok, pretty self-explanatory, clearly what I want to do here is backup an Azure Table so let’s select that guy. Note also that this is going backup to “AZURE JSON.GZ” – more on that shortly. Here’s what happens next:

There’s a bit going on here so let me explain the source side of things on the left first:
- I’ve plugged in my storage account and the access key
- I’ve used a regular expression to select all tables in the storage account (“BreachedAccount” holds email addresses, “BreachedUsername” holds, uh, usernames)
- I’m not removing old rows, I’d like to keep all my datas thank you very much
Now onto the right side of the image which is the target:
- I’m going to backup into the same storage account I used for the SQL Azure backup in part 1 except…
- …I’m going to put the backup into a new container called “redgate-table-backup” (this sits right next to the “automated-sql-export” container we used earlier)
- I’m going to remove backups older than a couple of weeks which is consistent with the strategy I employed in the SQL Azure backup in part 1
With that done, here’s what it’s going to do for us:

Now I could run this on a schedule and the configuration above is the same deal as with the database storage – each day at midnight local (remember, this is all running in the West US Azure data centre) the backup will run. But instead, I only want to run this once via the “Run now” button and I’ll explain why shortly.
Now we get a nice little confirmation of it and a list of any other backup services that are scheduled:

Ooh… start is imminent!
Once the backup starts you can drill down into it and see how things are progressing:

One minor gripe I have here is that 1% progress stays at 1% until… you hit 100%. Unfortunately there’s no API to get a row count of a table (yes, I know, this will seem very odd to many people and I hope it comes in a later release from Microsoft), and because of this, Red Gate don’t actually know how far through you are. Seeing the rows processed progressively appear under that is neat and the only real option, but ditch the progress indicator guys. Actually also on that, it’s worth nothing that this process is simply moving progressively through the table, it’s not like a SQL backup where there’s an atomic process that snapshots the whole thing.
Reviewing the backup
Keeping in mind I’m actually backing up two tables, the first one – a “mere” 6.4 million records containing only usernames – is available for download about a half hour later. Here it is in that storage container I created just for the Red Gate backups:

The completed status is also reflected in the earlier progress screen which shows the total number of records before moving onto the “BreachedAccount” table:

The usernames are only 70MB of zipped JSON and remember that’s now sitting in a geo-redundant storage container so has the Godzilla defence down. Like anything else in blob storage, I can simply download the backup and take a look inside. Now here’s the really important bit – everything in the file is just JSON:
{"Partition":"s","Key":"arannexo23","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.5968971Z"},
{"Partition":"s","Key":"arannnwrap","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.6278971Z"},
{"Partition":"s","Key":"arannwrap","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.6448971Z"},
{"Partition":"s","Key":"arano24","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.6578971Z"},
{"Partition":"s","Key":"arano8","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.6728971Z"},
{"Partition":"s","Key":"aranoach","Properties2":[{"K":"Websites","T":"String","V":"Snapchat"}],"Timestamp":"2014-01-01T21:27:10.6838971Z"},
What’s great about this is that it’s universal. This isn’t a proprietary Red Gate format that locks you to their view of the world; this is something you can drop straight into any other product that can talk JSON (or parse a text file, for that matter). I made similar comments when I originally wrote about SQL Source Control insofar as they were just generating and storing TSQL and not using some fancy proprietary format.
Incidentally, I partitioned the table above by using the first letter of the username so you’re looking at the “s” partition and the first username is sarannexo23, the next is sarannnwrap and so on.
Impact on performance and – oh boy – bandwidth
So what about performance? I mean can you expect an impact on the perf of the system that is dependent on the Table Storage? Let’s check using my How Fast Is Azure Table Storage tool:

Now I’ve seen this as fast as 4ms but I think we can fairly say that things are ticking along with no observable impact. Certainly other anecdotal tests had the same result so it’s not like the “old days” of only backing up the SQL DB out of hours because you’re scared of knocking people offline through crappy response times.
Anyway, the backup of the big table continued seamlessly until… this happened:

As it turns out, 160 million odd table records takes up a bit of space. Not a ridiculous amount, mind you, somewhere in the order of 30GB. The problem was that backing them up uses up a whole bunch of egress data well in excess of the storage size itself and adds a large number of transactions. Surprise, surprise. I did wonder for a moment if Red Gate’s service might be within the Azure data centre and not incur any egress charges, but then my bill did this:

Clearly when I’m micro optimising to the byte of trying to save mere bytes of data, these figures raise some eyebrows.
Now I actually took two shots at this entire exercise and in between them spoke with the good folks at Red Gate directly to clarify some facts (this is why you may see some dates a week earlier than others). I had a bunch of questions about how the service was put together and particularly given that what I’m talking about has a cost impact, I wanted to get my facts straight.
Red Gate’s service runs in the East US Azure data centre which means that in a case like mine above where the table storage is in the West US data centre, the bytes have got a way to travel. This means two things: Firstly, it’s going to take a while for large data sets (you can see I’m getting 9.49GB per hour) and secondly, I’m going to pay for the bandwidth because it’s leaving the data centre (it’s “egress” data). Now, if my table storage was in the East US data centre – the same one as Red Gate’s service – I wouldn’t pay a cent for the bandwidth because of this:

Get it?
Data transfers between Windows Azure services located within the same datacenter are not subject to any charge.
There’s a profoundly simple solution to the bandwidth problem: Red Gate needs to put their service in each data centre. Of course in reality it’s probably not quite that simple but it would mean that customers no longer incur bandwidth charges which in a case like mine, is pretty damn important. Clearly though, this is not a trivial activity for Red Gate nor (I imagine) is it a cheap one so the only thing that’s going to make it happen is customer demand. If you think this service is as good as I do, make your voice heard to Red Gate and leave a comment here as I’d love to see sufficient demand for them to build this service out further.
Bandwidth be damned, let’s run this thing!
Now let me explain why I just ran the damn thing again anyway: I’ve invested a huge amount of effort in this project and by all accounts it has become rather valuable. I’d hate to lose this data. Yes, I could reconstruct it from the original data sources (it’s only the breaches that are in Table Storage) but this would be extremely time consuming and frankly, I’m willing to pay a bit for the insurance of having this data versioned and protected from more than just an unplanned Japanese monster attack. Let’s proceed and then I’ll explain the cost situation.
Moving on, I let the whole process run again after bailing out the first time and about eleven and a half hours later, I get this:
![image[15]](https://lh5.ggpht.com/-Pz_PTB06xjE/Uudulk1_AJI/AAAAAAAAGXA/LvXtYFpZnFk/s1600-h/image152.png?ref=troyhunt.com "image[15]")
This is neat – the summary is nice and being proactively told when things are done is handy too. There are about 160 million rows there which is what I expected; it looks like the transfer size is unexpectedly low though – only about 22GB. Let’s take a look at the Table Storage monitoring:

There’s the important figure – 116.76GB of egress data in the last 24 hours. Normally I’d expect to see about a gig (remember, this is usually only about table storage to web site traffic) so call it maybe 115GB on top of the usual pattern. Why 115GB when the earlier email reported 22GB? This is one of the things I spoke to them about and apparently they’re pulling the data with version 2.x of the Azure Storage Client and not yet taking of advantage of version 3 (which admittedly only dropped last month) with the ability to pull the data down in JSON rather than AtomPub. This significantly changes the size of the request and especially the response with anywhere up to a 77% reduction per Microsoft’s example in that link. That’s massive so hopefully an upgrade is on the roadmap.
Just as a sanity check on the performance, here’s NewRelic’s view of things over the same period:

The spike around 21:00 is Kudu working on some deployments so ignore that, the main thing is that the system ticked along stably doing its job in less than 50ms most of the time. Even though the Azure monitoring chart shows increased latency over the same period (I assume due to the nature of the queries Red Gate is making), the end user experience hasn’t suffered.
Back to the cost – in the background of the earlier screen showing the bandwidth calculator, you’ll see that 115GB is selected on the slider and that it costs $13.20. That’s all. Just over three coffees on my cappuccino scale. I’m more than happy to pay this to have my data backed up – it’s nothing for what it does. But of course you also pay for transactions too and you can see about 3.6 million of those on the monitoring screen but they don’t matter because it’s only 10c for a million of them so we can ignore that cost. The fact that I’m paying Microsoft for it rather than Red Gate may seem a little unfair but it is what it is and I now have a proper backup of a very valuable piece of work. But this is also why I didn’t put this backup on a schedule – I don’t want to get hit with this cost on a regular basis. Having said that, if the bandwidth usage did reduce by 77% with a move to the newer storage client library and the cost came down to $3.04, perhaps running it again after each load of more breach data would be palatable.
But here’s the thing with all of this – I’m special. No really, it’s not just my mother saying this; my case is very unusual for a number of reasons. Firstly, I’ve got a 160-freakin'-million rows of data which is almost certainly on the upper-end of table storage use cases. Secondly, this isn’t transactional data insofar as it’s not something that people are regularly changing – it only changes when I load new breaches which means it doesn’t need the same backup schedule as my SQL Azure data. And finally, I don’t make any money out of this thing so every single dollar I spend comes out of my cafe habit rather than from revenue (although I’ll be claiming the tax deductions, dammit!)
Reviewing the results and exploring restore
When all the dust finally settled and the backups completed, here’s what I was left with:
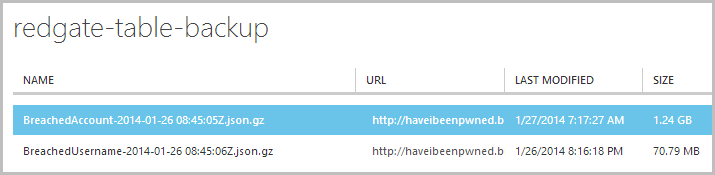
We’ve already seen the “BreachedUsername” table data, the big fella is the “BreachedAccount” table which has now been zipped down to only 1.24GB. As with the first table, I can now download this and add it to my local archive strategy in addition to the fact that it sits up in a geo-redundant container in Azure. Now of course I do pay for this storage as well, thing is though it’s at a rate of about 7.5c per GB per month so for about 1.3GB of data for both tables that’s less than 10c a month. Quite reasonable, wouldn’t you say? :)
Incidentally, that 1.24GB file extracted out to 21.4GB on my local file system so that should give you some idea of the data size if you’re trying to compare this example with your own scenario.
Now if – if – things go horribly wrong and I need to get this data from the storage in that last image back into the Azure Table Storage construct it came from in the first place, I can just go right back to the start and repeat the process in reverse:
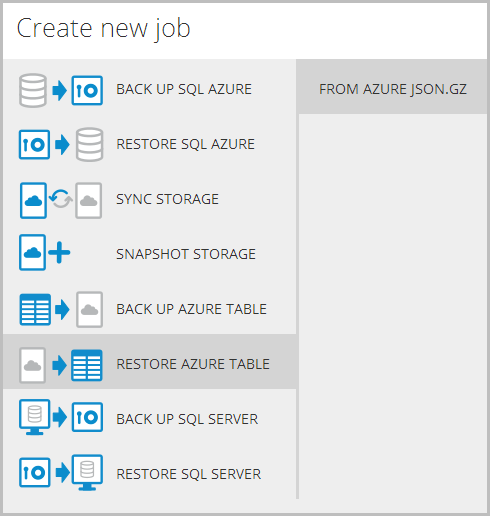
And you know the best thing about this? That’ll be ingress data and I won’t pay a cent for it!
Cheating the system with geo-redundant read access
In part 1 I mentioned the “Read Access Geo-Redundant” option for storage and pointed to Scott Gu’s post on the subject where he explains that what you get with this is the ability to access your replicated data from the secondary storage location in read only mode. Enabling this simply means selecting the appropriate replication option in the storage configuration:
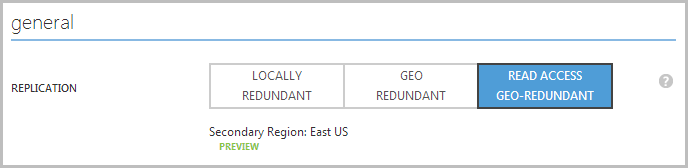
Hang on – I’m replicating to the East US Azure data centre? The one where the Red Gate service is running from? I wonder what we could do with that:
Read only access is enabled for all your data, which is replicated in the secondary storage region. This gives you the ability to access your data from multiple locations.
Ah, interesting, and what would I pay for the privilege of being able to read from the secondary storage location?
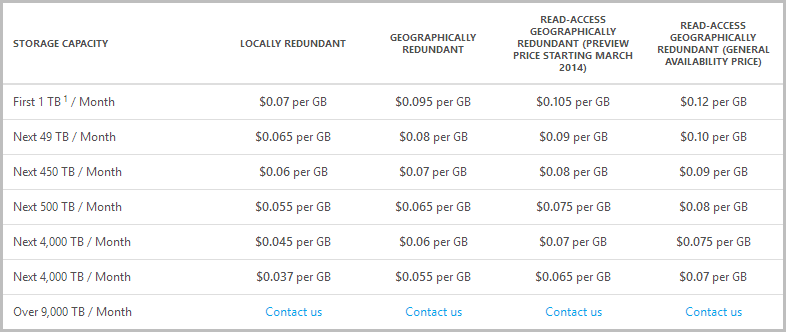
So for 30GB of table storage data I’m looking at an additional 30c a month during the preview pricing phase or a lofty 75c increase from the time of general availability (does this include the storage price reduction announced a few days ago?) Compared to copping $13 for bandwidth on every single backup, I reckon that’s a pretty good deal!
Now for the caveats: Firstly, you don’t get to choose where your data is geo-replicated to, it will automatically default to another data centre in the same region so if, say, you stand your storage up in one of the European or Asian data centres, you’re flat out of luck. Secondly, I haven’t tested this and I haven’t verified that there are no egress charges, but assuming Red Gate’s message on the location of the service stacks up and Microsoft does indeed not charge for internal traffic (which has certainly been my experience to date), there’s no reason why this wouldn’t be a significantly more cost effective option.
Summary
The most important thing out of this entire exercise is that I have backups. Proper backups, not just the “we’ll save your arse when Godzilla hits” backups. Honestly folks, start there and everything else is a distant second. Except for restores…
Now I haven’t had to restore to Azure and hopefully I never will, but I have been able to download and restore the SQL Azure .bacpac locally in part 1 and I have been able to extract the zipped JSON and, well, open it in Notepad – which is fine. All the data for both mediums is easily accessible via common tools and that’s the really essential bit.
In time, I expect this landscape will change because the nature of “The Cloud” in general and Azure specifically is that a lot of stuff happens very quickly. Maybe Red Gate will deploy the service to other Azure Data centres, maybe they’ll use the newer storage libraries or maybe Microsoft will just implement their own solution, who knows. What I do know for the moment is that both these processes – SQL Azure automated export in part 1 and Red Gate’s cloud service in part 2 – are dead easy to set up and absolutely invaluable. That’s something I’ll gladly dip into my coffee budget for.