
When it comes to website security, the most ubiquitous indication that the site is “secure” is the presence of transport layer protection. The assurance provided by the site differs between browsers, but the message is always the same; you know who you’re talking to, you know your communication is encrypted over the network and you know it hasn’t been manipulated in transit:
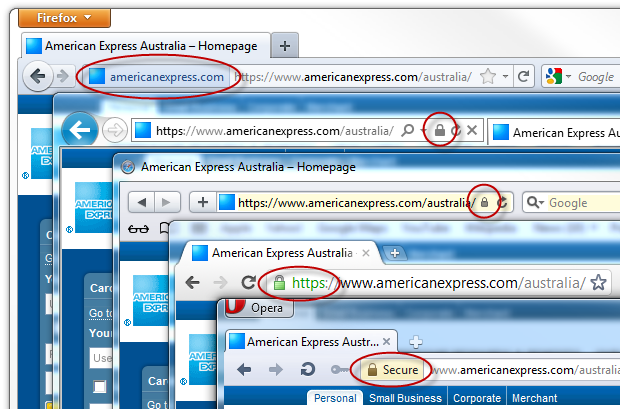
HTTPS, SSL and TLS (we’ll go into the differences between these shortly), are essential staples of website security. Without this assurance we have no confidence of who we’re talking to and if our communications – both the data we send and the data we receive – is authentic and has not been eavesdropped on.
But unfortunately we often find sites lacking and failing to implement proper transport layer protection. Sometimes this is because of the perceived costs of implementation, sometimes it’s not knowing how and sometimes it’s simply not understanding the risk that unencrypted communication poses. Part 9 of this series is going to clarify these misunderstandings and show to implement this essential security feature effectively within ASP.NET.
Defining insufficient transport layer protection
Transport layer protection is more involved than just whether it exists or not, indeed this entire post talks about insufficient implementations. It’s entirely possible to implement SSL on a site yet not do so in a fashion which makes full use of the protection it provides.
Here’s how OWASP summarises it:
Applications frequently fail to authenticate, encrypt, and protect the confidentiality and integrity of sensitive network traffic. When they do, they sometimes support weak algorithms, use expired or invalid certificates, or do not use them correctly.
Obviously this suggests that there is some variability in the efficacy of different implementations. OWASP defines the vulnerability and impact as follows:
| Threat Agents | Attack Vectors | Security Weakness | Technical Impacts | Business Impact | |
| Exploitability EASY | Prevalence UNCOMMON | Detectability AVERAGE | Impact MODERATE | ||
| Consider anyone who can monitor the network traffic of your users. If the application is on the internet, who knows how your users access it. Don’t forget back end connections. | Monitoring users’ network traffic can be difficult, but is sometimes easy. The primary difficulty lies in monitoring the proper network’s traffic while users are accessing the vulnerable site. | Applications frequently do not protect network traffic. They may use SSL/TLS during authentication, but not elsewhere, exposing data and session IDs to interception. Expired or improperly configured certificates may also be used. Detecting basic flaws is easy. Just observe the site’s network traffic. More subtle flaws require inspecting the design of the application and the server configuration. | Such flaws expose individual users’ data and can lead to account theft. If an admin account was compromised, the entire site could be exposed. Poor SSL setup can also facilitate phishing and MITM attacks. | Consider the business value of the data exposed on the communications channel in terms of its confidentiality and integrity needs, and the need to authenticate both participants. | |
Obviously this has a lot to do with the ability to monitor network traffic, something we’re going to look at in practice shortly. The above matrix also hints at the fact that transport layer protection is important beyond just protecting data such as passwords and information returned on web pages. In fact SSL and TLS goes way beyond this.
Disambiguation: SSL, TLS, HTTPS
These terms are all used a little interchangeably so let’s define them upfront before we begin using them.
SSL is Secure Sockets Layer which is the term we used to use to describe the cryptographic protocol used for communicating over the web. SSL provides an asymmetric encryption scheme which both client and server can use to encrypt and then decrypt messages sent in either direction. Netscape originally created SSL back in the 90s and it has since been superseded by TLS.
TLS is Transport Layer Security and the successor to SSL. You’ll frequently see TLS version numbers alongside SSL equivalent; TLS 1.0 is SSL 3.1, TLS 1.1 is SSL 3.2, etc. These days, you’ll usually see secure connections expressed as TLS versions:
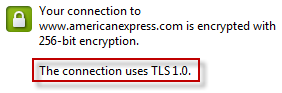
SSL / TLS can be applied to a number of different transport layer protocols: FTP, SMTP and, of course, HTTP.
HTTPS is Hypertext Transport Protocol Secure and is the implementation of TLS over HTTP. HTTPS is also the URI scheme of website addresses implementing SSL, that is it’s the prefix of an address such as https://www.americanexpress.com and implies the site will be loaded over an encrypted connection with a certificate that can usually be inspected in the browser.
In using these three terms interchangeably, the intent is usually the same in that it refers to securely communicating over HTTP.
Anatomy of an insufficient transport layer protection attack
In order to properly demonstrate the risk of insufficient transport security, I want to recreate a typical high-risk scenario. In this scenario we have an ASP.NET MVC website which implements Microsoft’s membership provider, an excellent out of the box solution for registration, login and credential storage which I discussed back in part 7 of this series about cryptographic storage. This website is a project I’m currently building at asafaweb.com and for the purpose of this post, it wasn’t making use of TLS.
For this example, I have a laptop, an iPad and a network adaptor which supports promiscuous mode which simply means it’s able to receive wireless packets which may not necessarily be destined for its address. Normally a wireless adapter will only receive packets directed to its MAC address but as wireless packets are simply broadcast over the air, there’s nothing to stop an adapter from receiving data not explicitly intended for it. A lot of built-in network cards don’t support this mode, but $27 from eBay and an Alfa AWUSO36H solves that problem:

In this scenario, the iPad is an innocent user of the ASafaWeb website. I’m already logged in as an administrator and as such I have the highlighted menu items below:
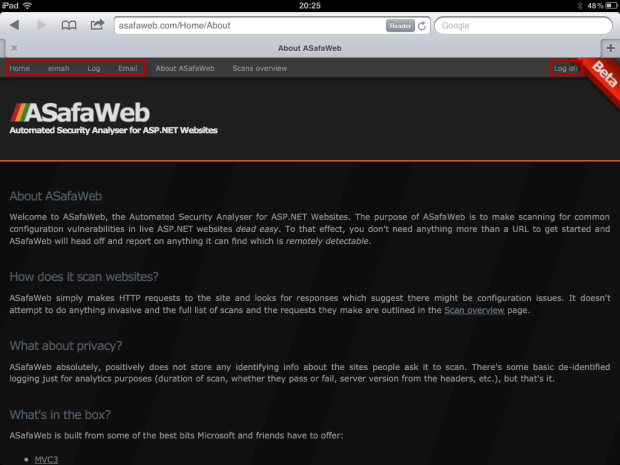
Whilst it’s not explicit on the iPad, this page has been loaded over HTTP. A page loaded over HTTPS displays a small padlock on the right of the tab:

The laptop is the attacker and it has no more rights than any public, non-authenticated user would. Consequently, it’s missing the administrative menu items the iPad had:
For a sense of realism and to simulate a real life attack scenario, I’ve taken a ride down to the local McDonald’s which offers free wifi. Both the laptop and the iPad are taking advantage of the service, as are many other customers scattered throughout the restaurant. The iPad has been assigned an IP address of 192.168.16.233 as confirmed by the IP Scanner app:

What we’re going to do is use the laptop to receive packets being sent across the wireless network regardless of whether it should actually be receiving them or not (remember this is our promiscuous mode in action). Windows is notoriously bad at running in promiscuous mode so I’m running the BackTrack software in a Linux virtual machine. An entire pre-configured image can be downloaded and running in next to no time. Using the pre-installed airodump-ng software, any packets the wireless adapter can pick up are now being recorded:
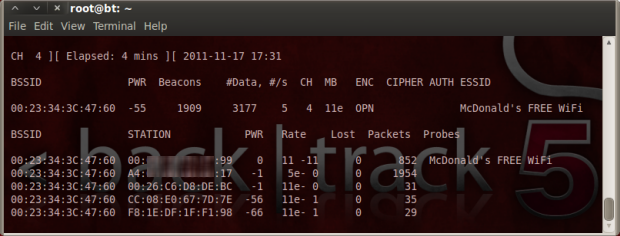
What we see above is airodump-ng capturing all the packets it can get hold of between the BSSID of the McDonald’s wireless access point and the individual devices connected to it. We can see the iPad’s MAC address on the second row in the table. The adapter connected to the laptop is just above that and a number of other customers then appear further down the list. As the capture runs, it’s streaming the data into a .cap file which can then be analysed at a later date.
While the capture ran, I had a browse around the ASafaWeb website on the iPad. Remember, the iPad could be any public user – it has absolutely no association to the laptop performing the capture. After letting the process run for a few minutes, I’ve opened up the capture file in Wireshark which is a packet capture and analysis tool frequently used for monitoring and inspecting network traffic:
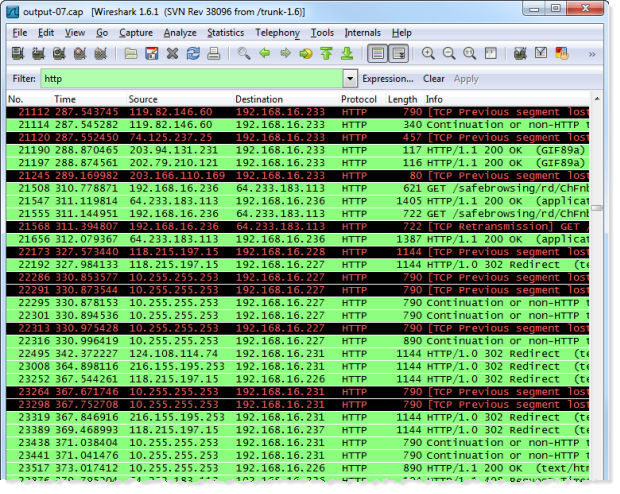
In this case, I’ve filtered the traffic to only include packets sent over the HTTP protocol (you can see this in the filer at the top of the page). As you can see, there’s a lot of traffic going backwards and forwards across a range of IP addresses. Only some of it – such as the first 6 packets – comes from my iPad. The rest are from other patrons so ethically, we won’t be going anywhere near these. Let’s filter those packets further so that only those originating from my iPad are shown:
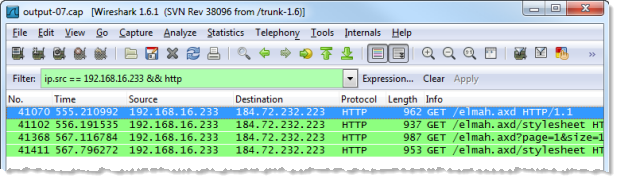
Now we start to see some interesting info as the GET requests for the elmah link appear. By right clicking on the first packet and following the TCP stream, we can see the entire request:
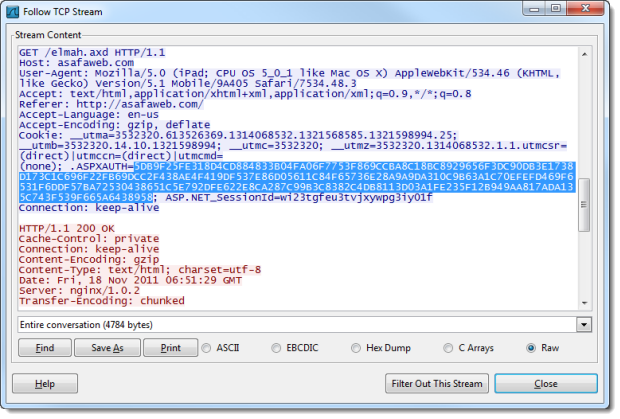
This is where it gets really interesting: each request any browser makes to a website includes any cookies the website has set. The request above contains a number of cookies, including one called “.ASPXAUTH”. This cookie is used by the membership provider to persist the authenticated state of the browser across the non-persistent, stateless protocol that is HTTP. On the laptop, I’m running the Edit This Cookie extension in Chrome which enables the easy inspection of existing cookies set by a website. Here’s what the ASafaWeb site has set:
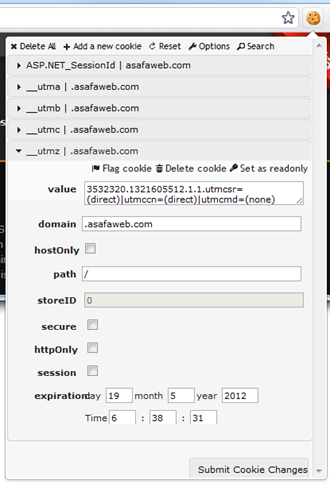
Ignore the __utm prefixed cookies – this is just Google Analytics. What’s important is that because this browser is not authenticated, there’s no “.ASPXAUTH” cookie. But that’s easily rectified simply by adding a new cookie with the same name and value as we’ve just observed from the iPad:
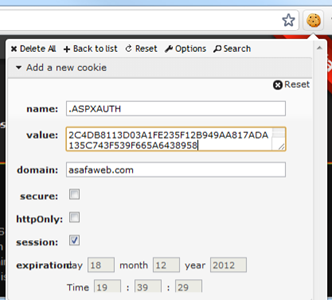
With the new authentication cookie set it’s simply a matter of refreshing the page:
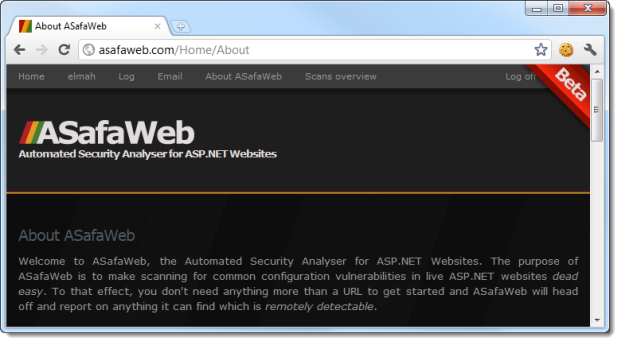
Bingo. Insufficient transport layer protection has just allowed us to hijack the session and become an administrator.
What made this possible?
When I referred to “hijack the session”, what this means is that the attacker was able to send requests which as far as the server was concerned, continue the same authentication session as the original one. In fact the legitimate user can continue using the site with no adverse impact whatsoever; there are simply two separate browsers authenticated as the same user at the same time. This form of session hijacking where packets are sniffed in transit and the authentication cookie recreated is often referred to as sidejacking, a form of session hijacking which is particularly vulnerable to public wifi hotspots given the ease of sniffing packets (as demonstrated above).
This isn’t a fault on McDonald’s end or a flaw with the membership provider nor is it a flaw with the way I’ve configured it, the attack above is simply a product of packets being sent over networks in plain text with no encryption. Think about the potential opportunities to intercept unencrypted packets: McDonald’s is now obvious, but there are thousands of coffee shops, airline lounges and other public wireless access points which make this a breeze.
But it’s not just wifi, literally any point in a network where packets transit is at risk. What happens upstream of your router? Or within your ISP? Or at the gateway of your corporate network? All of these locations and many more are potential points of packet interception and when they’re flying around in the clear, getting hold of them is very simple. In some cases, packet sniffing on a network can be a very rudimentary task indeed:

Many people think of TLS as purely a means of encrypting sensitive user data in transit. For example, you’ll often see login forms posting credentials over HTTPS then sending the authenticated user back to HTTP for the remainder of their session. The thinking is that once the password has been successfully protected, TLS no longer has a role to play. The example above shows that entire authenticated sessions need to be protected, not just the credentials in transit. This is a lesson taught by Firesheep last year and is arguably the catalyst for Facebook implementing the option of using TLS across authenticated sessions.
The basics of certificates
The premise of TLS is centred around the ability for digital certificates to be issued which provide the public key in the asymmetric encryption process and verify the authenticity of the sites which bear them. Certificates are issued by a certificate authority (CA) which is governed by strict regulations controlling how they are provisioned (there are presently over 600 CAs in more than 50 countries). After all, if anyone could provision certificates then the foundation on which TLS is built would be very shaky indeed. More on that later.
So how does the browser know which CAs to trust certificates from? It stores trusted authorities which are maintained by the browser vendor. For example, Firefox lists them in the Certificate Manager (The Firefox trusted CAs can also be seen online):
Microsoft maintains CAs in Windows under its Root Certificate Program which is accessible by Internet Explorer:
Of course the browser vendors also need to be able to maintain these lists. Every now and then new CAs are added and in extreme cases (such as DigiNotar recently), they can be removed thus causing any certificates issued by the authority to no longer be trusted by the browser and cause rather overt security warnings.
As I’ve written before, SSL is not about encryption. In fact it provides a number of benefits:
- It provides assurance of the identity of the website (site verification).
- It provides assurance that the content has not been manipulated in transit (data integrity).
- It provides assurance that eavesdropping has not occurred in transit (data confidentiality).
These days, getting hold of a certificate is fast, cheap and easily procured through domain registrars and hosting providers. For example, GoDaddy (who claim to be the world’s largest provider of certificates), can get you started from $79 a year. Or you can even grab a free one from StartSSL who have now been added to the list of trusted CAs in the major browsers. Most good web hosts also have provisions for the easy installation of certificates within your hosting environment. In short, TLS is now very cheap and very easily configured.
Edit: StartSSL is now dead, go and grab a cert from Let's Encrypt or wrap Cloudflare around it instead.
But of course the big question is “What does network traffic protected by TLS actually look like?” After applying a certificate to the ASafaWeb website and loading an authenticated page over HTTPS from my local network, it looks just like this:
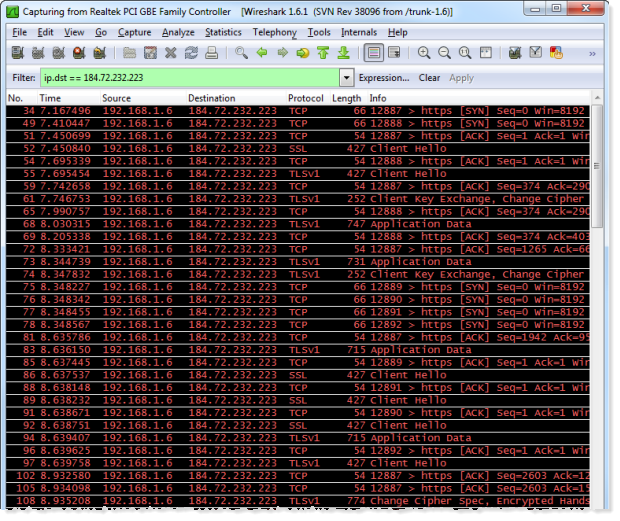
The destination IP address in the filter is the one behind asfaweb.com and whilst the packets obviously identify their intended destination, they don’t disclose much beyond that. In fact the TCP stream discloses nothing beyond the certificate details:
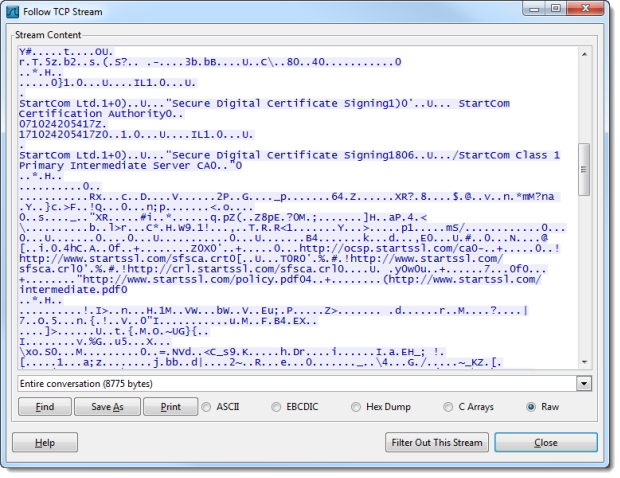
Of course we’d expect this info to be sent in the clear, it’s just what you’ll find when inspecting the certificate in the browser:
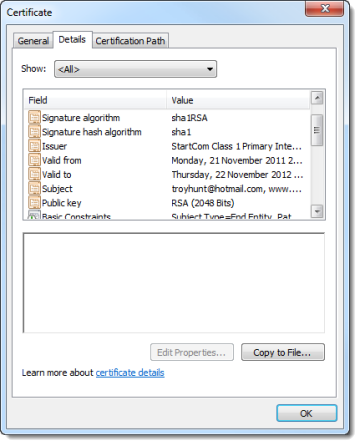
There’s really not much more to show; each of the packets in the Wireshark capture are nicely encrypted and kept away from prying eyes, which is exactly what we’d expect.
One last thing on certificates; you can always create what’s referred to as a self-signed certificate for the purposes of testing. Rather than being issued by a CA, a self-signed certificate is created by the owner so its legitimacy is never really certain. However, it’s a very easy way to test how your application behaves over HTTPS and what I’ll be using in a number of the examples in this post. There’s a great little blog post from Scott Gu on Enabling SSL on IIS 7.0 Using Self-Signed Certificates which walks through the process. Depending on the browser, you’ll get a very ostentatious warning when accessing a site with a self-signed certificate:
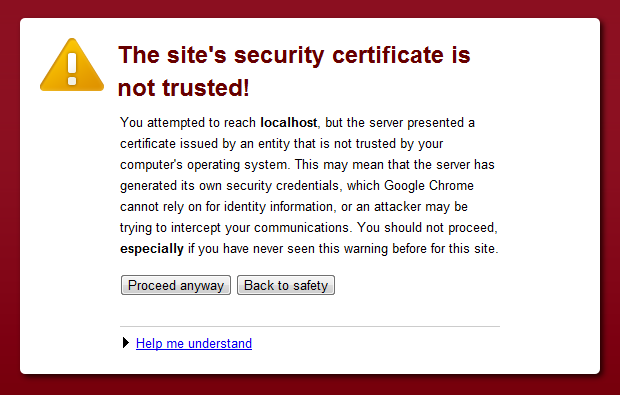
But again, for test purposes, this will work just fine.
Always use SSL for forms authentication
Clearly the problem in the session hijacking example above was that no TLS was present. Obviously assuming a valid certificate exists, one way of dealing with the issue would simply be to ensure login happens over TLS (any links to the login page would include the HTTPS scheme). But there’s a flaw with only doing this alone; let me demonstrate.
Here' we have the same website running locally over HTTPS using a self-signed certificate, hence the warning indicators in the URL bar:
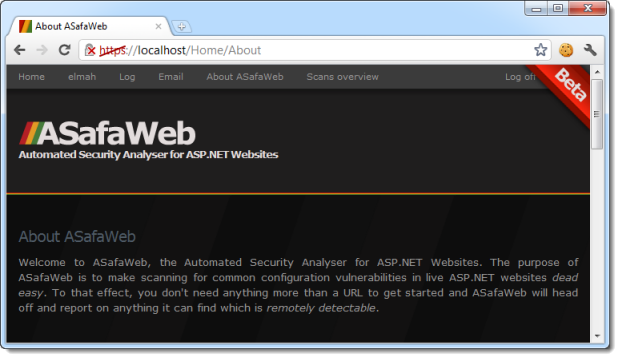
This alone is fine, assuming of course it had a valid certificate. The problem though, is this:
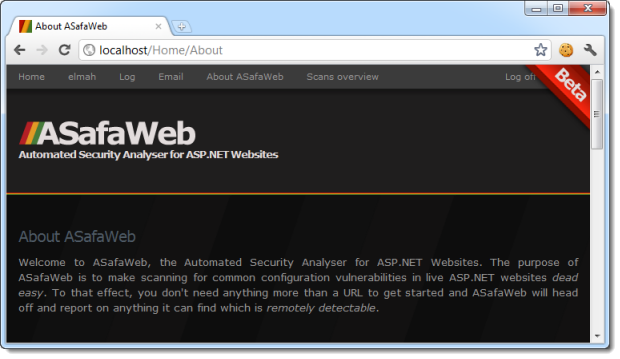
There is one subtle difference on this screen – the scheme is now HTTP. The problem though is that we’re still logged in. What this means is that the .ASPXAUTH cookie has been sent across the network in the clear and is open to interception in the same way I grabbed the one at McDonald’s earlier on. All it takes is one HTTP request to the website whilst I’m logged on – even though I logged on over HTTPS – and the session hijacking risk returns. When we inspect the cookie, the reason for this becomes clear:
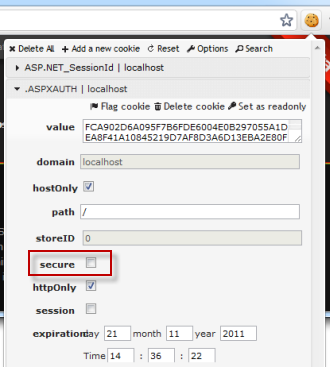
The cookie is not flagged as being “secure”. The secure cookie attribute instructs the browser as to whether or not it should send the cookie over an HTTP connection. When the cookie is not decorated with this attribute, the browser will send it along with all requests to the domain which set it, regardless of whether the HTTP or HTTPS scheme is used.
The mitigation for this within a forms authentication website in ASP.NET is to set the requireSSL property in the web.config to “true”:
<forms loginUrl="~/Account/LogOn" timeout="30" requireSSL="true" />
After we do this, the “secure” property on the cookie is now set and clearly visible when we look at the cookies passed over the HTTPS scheme:
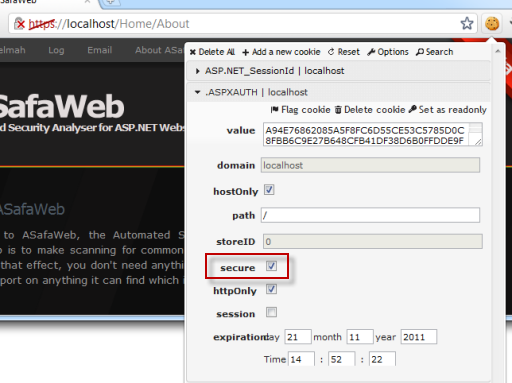
But go back to HTTP and the .ASPXAUTH cookie has completely disappeared – all that’s left is the cookie which persists the session ID:
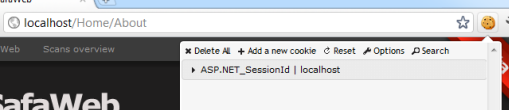
What the secure cookie does is ensures that it absolutely, positively cannot be passed over the network in the clear. The session hijacking example from earlier on is now impossible to reproduce. It also means that you can no longer login over the HTTP scheme:
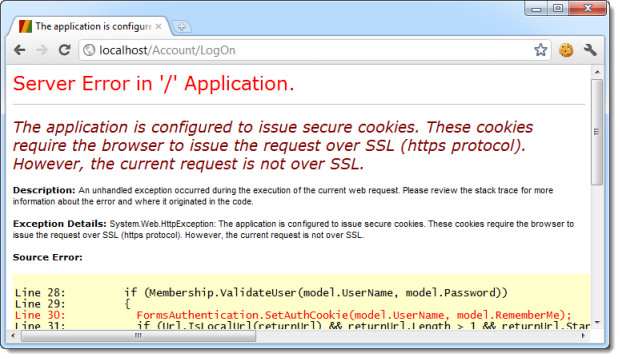
That’s a pretty self-explanatory error message!
Where possible, use SSL for cookies
In the example above, the membership provider took care of setting the .ASPXAUTH cookie and after correctly configuring the web.config, it also ensured the cookie was flagged as “secure”. But the extent of this is purely the auth cookie, nothing more. Take the following code as an example:
var cookie = new HttpCookie("ResultsPerPage", "50"); Response.Cookies.Add(cookie);
Let’s assume this cookie is used to determine how many results I want returned on the “Log” page of the admin section. I can define this value via controls on the page and it’s persisted via a cookie. I’m only ever going to need it on the admin page and as we now know, I can only access the admin page if already authenticated which, following the advice in the previous section, means I’ll have a secure auth cookie. But it doesn’t mean the “ResultsPerPage” cookie is secure:
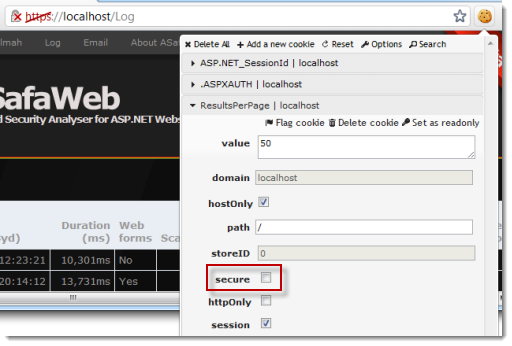
Now of course the necessity for the cookie to be marked as secure is a factor of the information being protected within it. Whilst this cookie doesn’t contain sensitive info, a better default position on a TLS-enabled site is to start secure and this can easily be configured via the web.config:
<httpCookies requireSSL="true" />
Once the requireSSL flag is set, we get the same protection that we got back in the forms authentication section for the auth cookie:
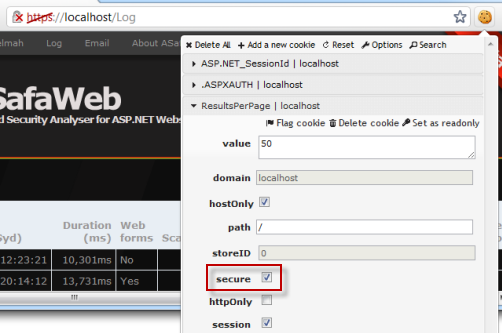
This is now a very different proposition as the cookie is afforded the same security as the auth cookie from earlier on. If the request isn’t made over HTTPS, the cookie simply won’t be sent over the network. But this setting means that every cookie can only be sent over HTTPS which means that even the ASP.NET_SessionId cookie is not sent over HTTP resulting in a new session ID for every request. In many cases this won’t matter, but sometimes more granularity is required.
What we can do is set the secure flag when the cookie is created rather than doing it globally in the web.config:
var cookie = new HttpCookie("ResultsPerPage", "50"); cookie.Secure = true; Response.Cookies.Add(cookie);
Whilst you’d only really need to do this when it’s important to have other cookies which can be sent across HTTP, it’s nice to have the option.
Just one more thing on cookies while we’re here, and it’s not really related to transport layer protection. If the cookie doesn’t need to be requested by client-side script, make sure it’s flagged as HTTP only. When you look back at the cookie information in the screen grabs, you may have noticed that this is set for the .ASPXAUTH cookie but not for the cookie we created by code. Setting this to “true” offers protection against malicious client-side attacks such as XSS and it’s equally easy to turn on either across the entire site in the web.config:
<httpCookies httpOnlyCookies="true" />
Or manually when creating the cookie:
var cookie = new HttpCookie("ResultsPerPage", "50"); cookie.HttpOnly = true; Response.Cookies.Add(cookie);
It’s cheap insurance and it means client script can no longer access the cookie. Of course there are times when you want to access the cookie via JavaScript but again, start locked down and open up from there if necessary.
Ask MVC to require SSL and link to HTTPS
Something that ASP.NET MVC makes exceptionally easy is the ability to require controllers or actions to only be served over HTTPS; it’s just a simple attribute:
[RequireHttps] public class AccountController : Controller
In a case like the account controller (this is just the default one from a new MVC project), we don’t want any of the actions to be served over HTTP as they include features for logging in, registering and changing passwords. This is an easy case for decorating the entire controller class but it can be used in just the same way against an action method if more granularity is required.
Once we require HTTPS, any HTTP requests will be met with a 302 (moved temporarily) response and then the browser redirected to the secure version. We can see this sequence play out in Fiddler:

But it’s always preferable to avoid redirects as it means the browser ends up making an additional request, plus it poses some other security risks we’ll look at shortly. A preferable approach is to link directly to the resource using the HTTPS scheme and in the case of linking to controller actions, it’s easy to pass in the protocol via one of the overloads:
@Html.ActionLink("Log on", "LogOn", "Account", "https", null, null, null,
null)
Unfortunately the only available ActionLink overload which takes a protocol also has another four redundant parameters but regardless, the end result is that an absolute URL using the HTTPS scheme is emitted to the markup:
<a href="https://localhost/Account/LogOn">
Applying both these techniques gives the best of both worlds: It’s easy to link directly to secure versions of actions plus your controller gets to play policeman and ensure that it’s not possible to circumvent HTTPS, either deliberately or by accident.
Time limit authentication token validity
While we’re talking about easily configurable defences, a very “quick win” – albeit not specific to TLS – is to ensure the period for which an authentication token is valid is kept to a bare minimum. When we reduce this period, the window in which the session may be hijacked is reduced.
One way of reducing this window is simply to reduce the timeout set in the forms authentication element of the web.config:
<forms loginUrl="~/Account/LogOn" timeout="30" />
Whilst the default in a new ASP.NET app (either MVC or web forms) is 30 minutes, reducing this number to the minimum practical value offers a certain degree of security. Of course you then trade off usability, but that’s often the balance we work with in security (two factor authentication is a great example of this).
But even shorter timeouts leave a persistent risk; if the hijacker does get hold of the session, they can just keep issuing requests until they’re done with their malicious activities and they’ll remain authenticated. One way of mitigating this risk – but also at the cost of usability – is to disable sliding expiration:
<forms loginUrl="~/Account/LogOn" timeout="30" slidingExpiration="false" />
What this means is that regardless of whether the authenticated user keeps sending requests or not, the user will be logged out after the timeout period elapses once they’re logged in. This caps the window of session hijacking risk.
But the value of both these settings is greater when no TLS exists. Yes, sessions can still be hijacked when TLS is in place, but it’s an additional piece of security that’s always nice to have in place.
Always serve login pages over HTTPS
A fairly common practice on websites is to display a login form on each page. Usually these pages are served up over HTTP, after all, they just contain public content. Singapore Airlines uses this approach so that as you navigate through the site, the login form remains at the top left of the screen:
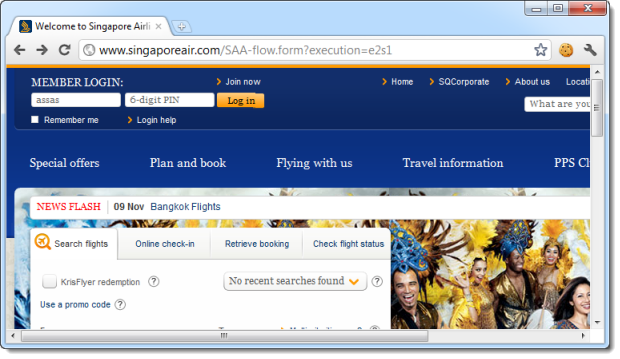
In order to protect the credentials in transit, they then post to an HTTPS address:
<form id="headerLoginForm"
action="https://www.singaporeair.com/kfHeaderLogin.form" method="post">
Think of the HTTP login form scenario like this:

This method will encrypt the credentials before posting them, but there’s one very major flaw in the design; it’s wide open to a man in the middle attack. An MITM attack works by a malicious party intercepting and manipulating the conversation between client and server. Earlier on I explained that one of the benefits offered by TLS was that it “provides assurance that the content has not been manipulated in transit”. Consider that in the following MITM scenario:
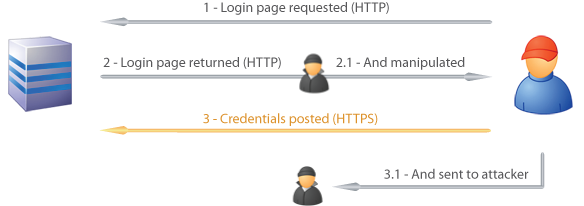
Because the login form was loaded over HTTP, it was open to modification by a malicious party. This could happen at many different points between the client and the server; the client’s internet gateway, the ISP, the hosting provider, etc. Once that login form is available for modification, inserting, say, some JavaScript to asynchronously send the credentials off to an attacker’s website can be done without the victim being any the wiser.
This is not the stuff of fiction; precisely this scenario was played out by the Tunisian government only a year ago:
The Tunisian Internet Agency (Agence tunisienne d'Internet or ATI) is being blamed for the presence of injected JavaScript that captures usernames and passwords. The code has been discovered on login pages for Gmail, Yahoo, and Facebook, and said to be the reason for the recent rash of account hijackings reported by Tunisian protesters.
And:
There is an upside however, as the embedded JavaScript only appears when one of the sites is accessed with HTTP instead of HTTPS. In each test case, we were able to confirm that Gmail and Yahoo were only compromised when HTTP was used.
The mitigation for this risk is simply not to display login forms on pages which may be requested over HTTP. In a case like Singapore Airlines, either each page needs to be served over HTTPS or there needs to be a link to an HTTPS login page. You can’t have it both ways.
OWASP also refers to this specific risk in the TLS cheat sheet under Use TLS for All Login Pages and All Authenticated Pages:
The login page and all subsequent authenticated pages must be exclusively accessed over TLS. The initial login page, referred to as the "login landing page", must be served over TLS. Failure to utilize TLS for the login landing page allows an attacker to modify the login form action, causing the user's credentials to be posted to an arbitrary location.
Very clear indeed.
But there’s also a secondary flaw with loading a login form over HTTP then posting to HTTPS; there’s no opportunity to inspect the certificate before sending sensitive data. Because of this, the authenticity of the site can’t be verified until it’s too late. Actually, the user has no idea if any transport security will be employed at all and without seeing the usual browser indicators that TLS is present, the assumption would normally be that no TLS exists. There’s simply nothing visible to indicate otherwise.
Try not to redirect from HTTP to HTTPS
One of the risks that remains in an HTTPS world is how the user gets there to begin with. Let’s take a typical scenario and look at American Express. Most people, when wanting to access the site will type this into their browser’s address bar:
All browsers will default this address to use the HTTP scheme so the request they actually make is:
http://www.americanexpress.com
But as you can see from the browser below, the response does not use the HTTP scheme at all, rather it comes back with the landing page (including login facility) over HTTPS:
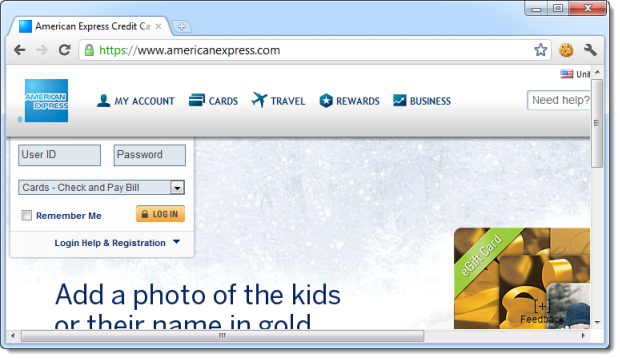
What’s actually happening here is that Amex is receiving the HTTP request then returning an HTTP 301 (moved permanently) response and asking the browser to redirect to https://www.americanexpress.com/. We can see this in Fiddler with the request in the top half of the screen and the response at the bottom:
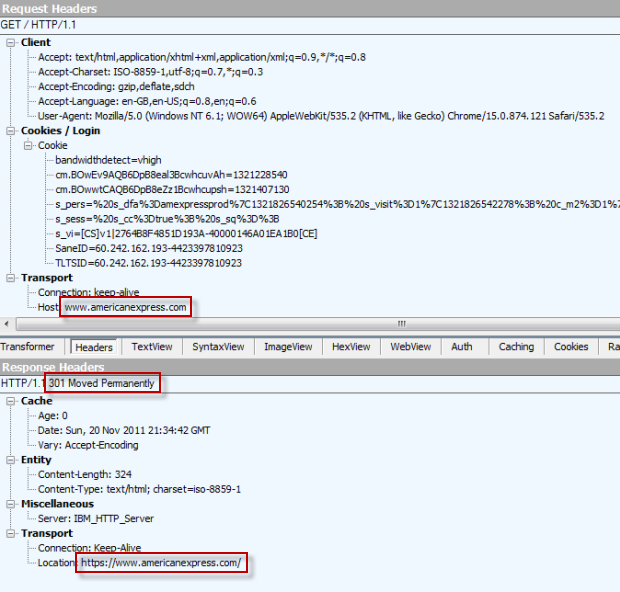
Because that first request is being made over HTTP it’s vulnerable to manipulation in the same way as the Tunisian example earlier on in that it can be modified in transit. In fact there’s nothing stopping a malicious party who was able to manipulate the response from changing the redirect path (or any other part of the response) to something entirely different or just retuning an HTTP page with modified login controls (again, think back to Tunisia). All of this is simply because the request sequence started out over an insecure protocol.
It was only a few years back that the risk this practice poses was brought into the spotlight by Moxie Marlinspike when he created SSL Strip. What Moxie showed us is the ease with which transport security can be entirely removed by a MITM simply intercepting that first HTTP request then instead of allowing the redirect to HTTPS, sending the response back to the client in HTTP and then proxying requests back to the server over HTTPS. Unless explicitly looking for the presence of HTTPS (which most users wouldn’t consciously do), the path has now been paved to observe credentials and other sensitive data being sent over plain old unencrypted HTTP. The video on the website is well worth a watch and shows just how easily HTTPS can be circumvented when you begin with a dependency on HTTP (also consider this in the context of the previous section about loading login forms over HTTP).
In a perfect world, the solution is to never redirect; the site would only load if the user explicitly typed a URL beginning with the HTTPS scheme thus mitigating the threat of manipulation. But of course that would have a significant usability impact; anyone who attempted to access a URL without a scheme would go nowhere.
Until recently, OWASP published a section titled Do not perform redirects from non-TLS to TLS login page (it’s still there, just flagged as “removed”). Their suggestion was as follows:
It is recommended to display a security warning message to the user whenever the non-TLS login page is requested. This security warning should urge the user to always type "HTTPS" into the browser or bookmark the secure login page. This approach will help educate users on the correct and most secure method of accessing the application.
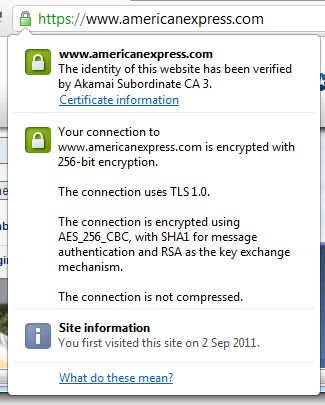
Obviously this has a major usability impact; asking the user to go back up to their address bar and manually change the URL seems ludicrous in a world of hyperlinks and redirects. This, unfortunately, is why the HTTP to HTTPS redirect pattern will remain for some time yet, but at least developers should be aware of the risk. The only available mitigation is to check the validity of the certificate before providing your credentials:
HTTP strict transport security
A potential solution to the risks of serving content over HTTP which should be secure is HTTP Strict Transport Security, or HSTS for short. The HSTS spec remains in draft form after originally being submitted to IETF around the middle of last year. The promise of the proposed spec is that it will provide facilities for content to be flagged as secure in a fashion that the browser will understand and that cannot be manipulated by a malicious party.
As tends to be the way with the web, not having a ratified spec is not grounds to avoid using it altogether. In fact it’s beginning to be supported by major browsers, most notably Chrome who adopted it back in 2009 and Firefox who took it on board earlier this year. As is also often the case, other browsers – such as Internet Explorer and Safari – don’t yet support it at all and will simply ignore the HSTS header.
So how does HSTS work? Once a supporting browser receives this header returned from an HTTPS request (it may not be returned over HTTP – which we now know can’t be trusted – or the browser will ignore it), it will only issue subsequent requests to that site over the HTTPS scheme. The "Strict-Transport-Security" header also returns a “max-age” attribute in seconds and until this period has expired, the browser will automatically translate any HTTP requests into HTTPS versions with the same path.
Enforcing HTTPS and supporting HSTS can easily be achieved in an ASP.NET app; it’s nothing more than a header. The real work is done on the browser end which then takes responsibility for not issuing HTTP requests to a site already flagged as "Strict-Transport-Security". In fact the browser does its own internal version of an HTTP 301 but because we’re not relying on this response coming back over HTTP, it’s not vulnerable to the MITM attack we saw earlier.
The HSTS header and forceful redirection to the HTTPS scheme can both easily be implemented in the Application_BeginRequest event of the global.asax:
protected void Application_BeginRequest(Object sender, EventArgs e) { switch (Request.Url.Scheme) { case "https": Response.AddHeader("Strict-Transport-Security", "max-age=300"); break; case "http": var path = "https://" + Request.Url.Host + Request.Url.PathAndQuery; Response.Status = "301 Moved Permanently"; Response.AddHeader("Location", path); break; } }
With this in place, let’s take a look at HSTS in action. What I’m going to do is set the link to the site’s style sheet to explicitly use HTTP so it looks like this:
<link href="http://localhost/Content/Site.css" rel="stylesheet"
type="text/css" />
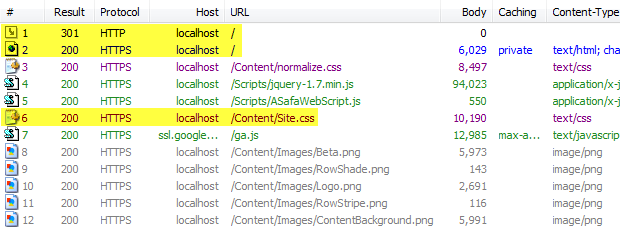
Now here’s what happens when I make an HTTP request to the site with Chrome:
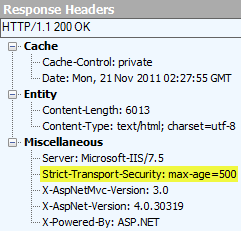
And this is the response header of the second request:
There are three important things to note here:
-
Request 1: The HTTP request is responded to with an HTTP 301 redirecting me to the HTTPS scheme for the same resource.
-
Request 2: The HTTPS redirect from the previous point returns the "Strict-Transport-Security" header in the response.
-
Request 6: This is to the style sheet which was explicitly embedded with an absolute link using the HTTP scheme but as we can see, the browser has converted this to use HTTPS before even issuing the request.
Going back to the original example where packets sent over HTTP were sniffed, if the login had been over HTTPS and HSTS was used, it would have been impossible for the browser to issue requests over HTTP for the next 500 seconds even if explicitly asked to do so. Of course this structure then disallows any content to be served over HTTP but in many cases, this is precisely the scenario you’re looking to achieve.
One final comment on HSTS, or rather the concept of forcing HTTPS requests; even when the "Strict-Transport-Security" header is not returned by the server, it’s still possible to ensure requests are only sent over HTTPS by using the HTTPS Everywhere plugin for Firefox. This plugin mimics the behaviour of HSTS and performs an in-browser redirect to the secure version of content for sites you’ve specified as being TLS-only. Of course the site still needs to support HTTPS in the first place, but where it does, the HTTPS Everywhere plugin will ensure all requests are issued across a secure connection. But ultimately this is only a mitigation you can perform as a user on a website, not as a developer.
Don’t mix TLS and non-TLS content
This might seem like a minor issue, but loading a page over TLS then including non-TLS content actually causes some fairly major issues. From a purely technical perspective, it means that the non-TLS content can be intercepted and manipulated. Even if it’s just a single image, you no longer have certainty of authenticity which is one of the key values that TLS delivers.
But the more obvious problem is that this will very quickly be brought to the attention of users of the webpage. The implementation differs from browser to browser, but in the case of Chrome, here’s what happens when content is mixed:
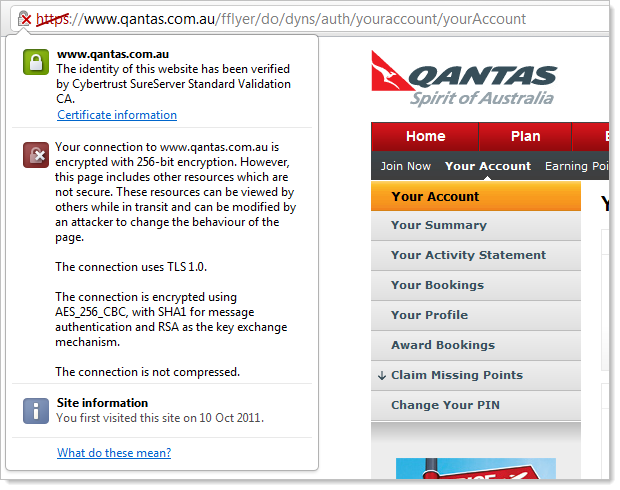
By striking out the padlock icon and the HTTPS scheme in the URL, the browser is sending a very clear warning to the user – don’t trust this site! The trust and confidence you’ve built with the user is very swiftly torn apart just by the inclusion of a single non-TLS asset on the page. The warning in the certificate info panel above is clear: you’re requesting insecure resources and they can’t be trusted to be authentic.
And that’s all it takes – one asset. In Qantas’ case, we can easily see this by inspecting the content in Fiddler. There’s just a single request out of about 100 which is loaded over HTTP:

And what would justify sacrificing properly implemented TLS? Just one little Flash file promoting Secret Santa:

More likely than not it’s an oversight on their part and it’s something to remain vigilant about when building your apps. The bigger problem this poses is that once you start desensitising users to security warnings, there’s a real risk that legitimate warnings are simply ignored and this very quickly erodes the value delivered by TLS.
Whilst mixed HTTPS and HTTP content is an easily solvable issue when all the content is served from the one site, it remains a constant challenge when embedding content from external resources. In fact some people argue that this is one of the reasons why the web has not switched to SSL-only yet. For example, Google AdSense doesn’t support SSL version of their ads. Not being able to display revenue generating advertising is going to be a deal-breaker for some sites and if they rely on embedding those ads on authenticated pages, some tough decisions and ultimately sacrifices of either security or dollars are going to need to be made.
But it’s not all bad news and many external services do provide HTTPS alternatives to ensure this isn’t a problem. For example, Google Analytics works just fine over HTTPS as does Twitter’s tweet button. Ironically that last link is presently returning mixed content itself:
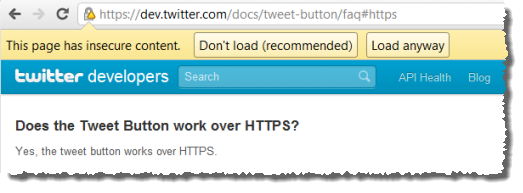
It just goes to show that as basic as the concept is, even the big guys get it wrong.
Sensitive data still doesn’t belong in the URL
One mechanism people tend to regularly use to persist data across requests is to pass it around via query strings so that the URL has all the information is needs to process the request. For example, back in part 3 about broken authentication and session management I showed how the “cookieless” attribute of the forms authentication element in the web.config could be set to “UseUri” which causes the session to be persisted via the URL rather than by using cookies. It means the address ends up looking something like this:
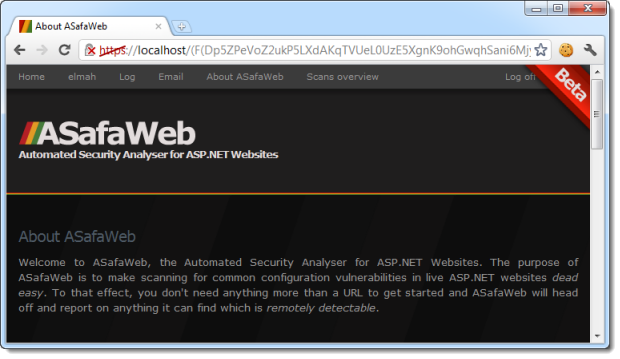
In the example I showed how this meant the URL could then be reused elsewhere and the session hijacked. Transport layer security changes nothing in this scenario. Because the URL contains sensitive data it can still be handed off to another party – either through social engineering or simple sharing – and the session hijacked.
OWASP also talks about keeping sensitive data out of the URL and identifies additional risks in the SSL cheat sheet. These risks include the potential caching of the page (including URL) on the user’s machine and the risk of the URL being passed in the referrer header when linking from one TLS site to another. Clearly the URL is not the right location to be placing anything that’s either sensitive, or in the case of the session hijacking example above, could be used to perform malicious activity.
The (lack of) performance impact of TLS
The process of encrypting and decrypting content on the web server isn’t free – it has a performance price. Opponents of applying TLS liberally argue that this performance impact is of sufficient significance that for sites of scale, the cost may well go beyond simply procuring a certificate and appropriately configuring the app. Additional processing power may be required in order to support TLS on top of the existing overhead of running the app over HTTP.
There’s an excellent precedent that debunks this theory: Google’s move to TLS only for Gmail. Earlier last year (before the emergence of Firesheep), Google made the call that all communication between Gmail and the browser should be secured by TLS. In Verisign’s white paper titled Protecting Users From Firesheep and other Sidejacking Attacks with SSL, Google is quoted as saying the following about the performance impact of the decision:
In order to do this we had to deploy no additional machines and no special hardware. On our production front-end machines, SSL/TLS accounts for less than 1% of the CPU load, less than 10KB of memory per connection and less than 2% of network overhead. Many people believe that SSL takes a lot of CPU time and we hope the above numbers (public for the first time) will help to dispel that.
Whilst the exact impact is arguable and certainly it will differ from case to case, Google’s example shows that TLS everywhere is achievable with next to no performance overhead.
Breaking TLS
Like any defence we apply in information security, TLS itself is not immune from being broken or subverted. We’ve looked at mechanisms to circumvent it by going upstream of secure requests and attacking at the HTTP level, but what about the certificate infrastructure itself?
Only a few months back we saw how vulnerable TLS can be courtesy of DigiNotar. The Dutch certificate authority demonstrated that a systemic breakdown in their own internal security could pave the way for a malicious party to issue perfectly legitimate certificates for the likes of Google and Yahoo! This isn’t the first time a CA has been compromised; Comodo suffered an attack earlier this year in the now infamous Comodo-gate incident in which one of their affiliates was breached and certificates issued for Skype and Gmail, among others.
Around the same time as the DigiNotar situation, we also saw the emergence of BEAST, the Browser Exploit Against SSL/TLS. What BEAST showed us is that an inherent vulnerability in the current accepted version of TLS (1.0), could allow an attacker to decipher encrypted cookies from the likes of PayPal. It wasn’t a simple attack by any means, but it did demonstrate that flaws exist in places that nobody expected could actually be exploited.
But the reality is that there remains numerous ways to break TLS and it need not always involve the compromise of a CA. Does this make it “insecure”? No, it makes it imperfect but nobody is about to argue that it doesn’t offer a significant advantage over plain old HTTP communication. To the contrary, TLS has a lot of life left and will continue to be a cornerstone of web security for many years to come.
Summary
Properly implementing transport layer protection within a web app is a lot of information to take on board and I didn’t even touch on many of the important aspects of certificates themselves; encryption strength (128 bit, 256 bit), extended validation, protecting private keys, etc.
Transport security remains one of those measures which whilst undoubtedly advantageous, is also far from fool proof. This comment from Moxie Marlinspike in the video on the SSL Strip page is testimony to how fragile HTTPS can actually be:
Lots of times the security of HTTPS comes down to the security of HTTP, and HTTP is not secure
What’s the solution? Many people are saying responsibility should fall back to DNS so that sites which should only be served over secure connections are designated outside of the transport layer and thus less prone to manipulation. But then DNS is not fool proof.
Ultimately we, as developers, can only work with the tools at our disposal and certainly there are numerous ways we can mitigate the risk of insufficient transport layer protection. But as with the other posts in this series, you can’t get things perfect and the more you understand about the potential vulnerabilities, the better equipped you are to deal with them.
As for the ASafaWeb website, you’ll now observe a free StartSSL certificate on the login page which, naturally, is loaded over TLS. Plus I always navigate directly to the HTTPS address by way of bookmark before authenticating. It’s really not that hard.
Resources
OWASP Top 10 for .NET developers series
|
1. Injection |